Pourquoi la signification statistique est-elle importante ?
Découvrez pourquoi la signification statistique est essentielle dans l’analyse de données, la recherche et la prise de décisions commerciales. Apprenez ce que sont les p-values, les tests d’hypothèse et comment interpréter correctement les résultats.
Pourquoi la signification statistique est-elle importante ?
La signification statistique est importante car elle mesure la probabilité qu’un résultat soit dû au hasard. Elle aide les chercheurs et les entreprises à distinguer les effets réels de la variation aléatoire, permettant ainsi de prendre des décisions en toute confiance sur la base de preuves fiables plutôt que sur la coïncidence.
Comprendre la signification statistique dans l’analyse de données moderne
La signification statistique constitue la base d’une prise de décision fondée sur des preuves, dans des secteurs allant de la recherche pharmaceutique au marketing digital et à la gestion de programmes d’affiliation. Fondamentalement, la signification statistique répond à une question essentielle : Le résultat observé est-il un effet réel ou simplement le fruit du hasard ? Cette distinction est cruciale, car les organisations investissent des ressources importantes sur la base des données, et tirer des conclusions erronées peut entraîner du gaspillage budgétaire, des stratégies inefficaces et des occasions manquées. En établissant des standards statistiques rigoureux, les professionnels peuvent mettre en œuvre des changements en toute confiance, sachant que leurs décisions reposent sur des preuves solides plutôt que sur des coïncidences.
L’importance de la signification statistique dépasse le cadre académique pour s’appliquer aux activités commerciales concrètes. Qu’il s’agisse d’un marketeur affilié testant une nouvelle stratégie promotionnelle, d’une entreprise pharmaceutique évaluant l’efficacité d’un médicament, ou d’une plateforme e-commerce optimisant son processus de commande, la signification statistique fournit le cadre objectif nécessaire pour valider les résultats. Sans ce cadre, il serait difficile de distinguer les fluctuations passagères des tendances significatives, ce qui pourrait mener à des décisions coûteuses fondées sur le bruit des données.
Les bases : p-values et tests d’hypothèse
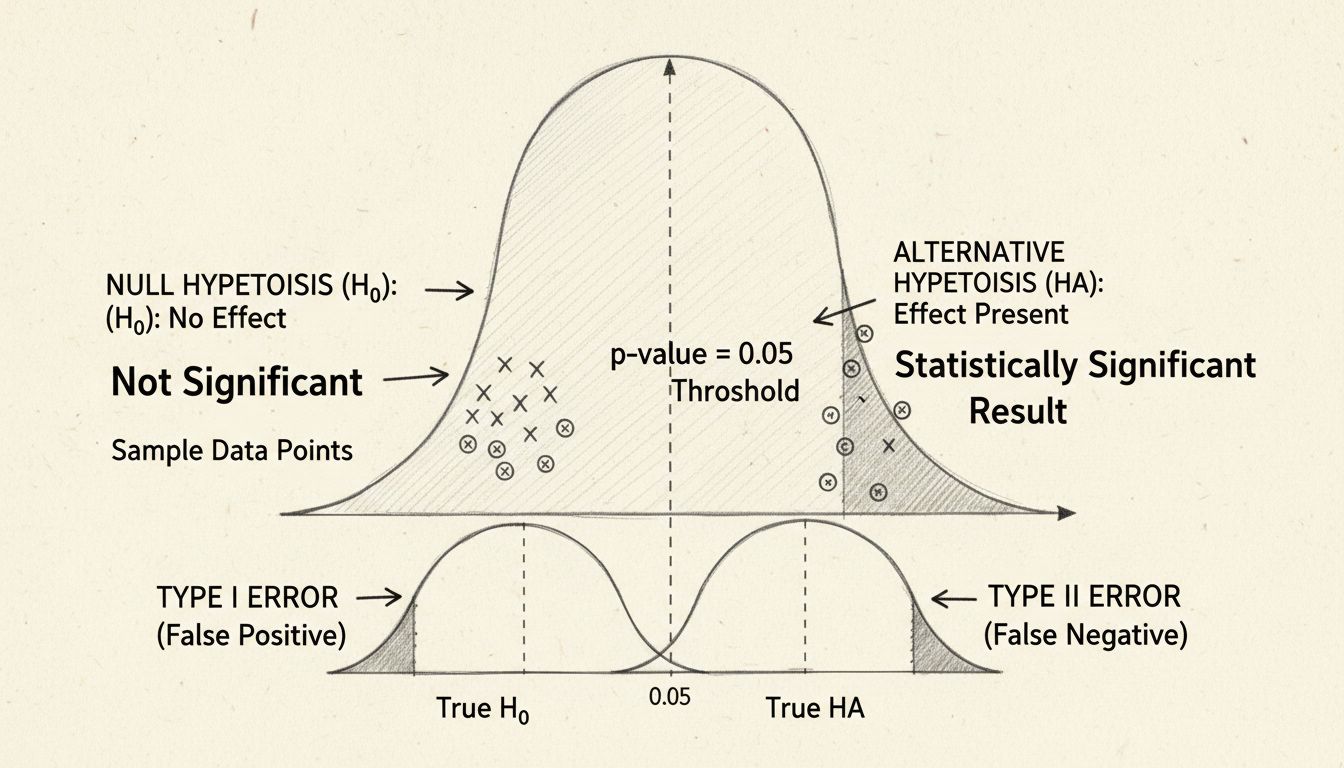
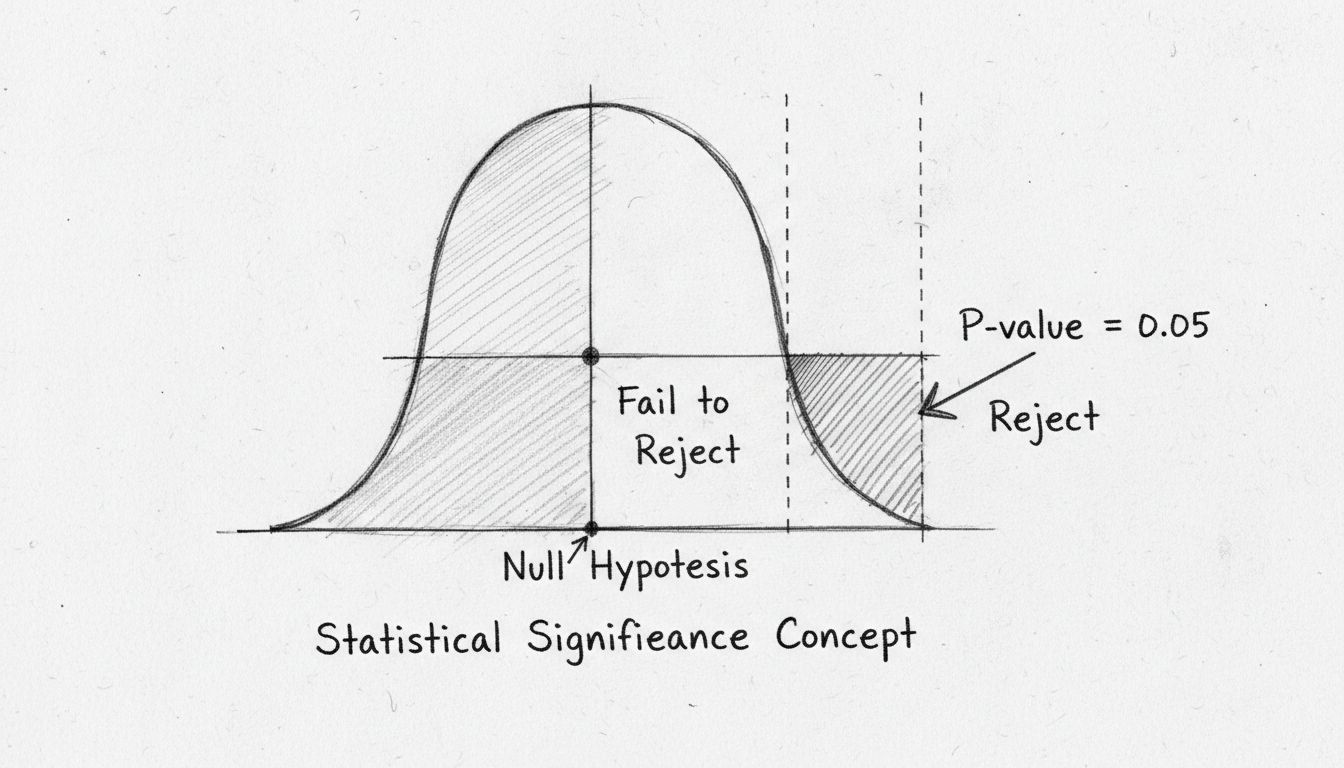
La p-value représente la probabilité d’obtenir des résultats aussi extrêmes que ceux mesurés, en supposant que l’hypothèse nulle (c’est-à-dire l’absence d’effet réel) est vraie. Cette mesure est devenue l’outil standard pour évaluer la signification statistique dans les milieux scientifiques et commerciaux. Une p-value de 0,05 ou moins est traditionnellement considérée comme statistiquement significative, ce qui signifie qu’il y a moins de 5 % de probabilité que le résultat observé soit simplement dû au hasard. Ce seuil, établi par le statisticien Ronald Fisher dans les années 1920, est devenu la norme car il équilibre la confiance et la faisabilité pratique.
Comprendre les p-values nécessite de savoir ce qu’elles représentent – et ce qu’elles ne représentent pas. Une idée reçue courante est qu’une p-value indique la probabilité que l’hypothèse nulle soit vraie ; c’est incorrect. En réalité, la p-value indique à quel point les données observées seraient probables si l’hypothèse nulle était vraie. Une petite p-value suggère une forte preuve contre l’hypothèse nulle, soutenant l’hypothèse alternative qu’un effet réel existe. Inversement, une grande p-value indique qu’il n’y a pas suffisamment de preuve pour rejeter l’hypothèse nulle ; cela ne prouve pas pour autant que l’hypothèse nulle est vraie, cela signifie simplement que les données ne fournissent pas de preuve convaincante contre elle.
Lancez votre programme d'affiliation aujourd'hui
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
Distinguer les effets réels des variations aléatoires
L’une des fonctions les plus cruciales de la signification statistique est de permettre de séparer les tendances véritables du bruit aléatoire dans les données. Dans tout ensemble de données, une certaine variation est inévitable en raison des erreurs d’échantillonnage, d’imprécisions de mesure et du hasard naturel. Sans tests de signification statistique, il est impossible de savoir si les différences observées sont le reflet d’effets réels ou simplement de cette variabilité inhérente. Par exemple, si un programme d’affiliation observe une augmentation de 2 % du taux de conversion après la mise en place d’un nouveau système de suivi, la signification statistique permet de savoir si cette amélioration est susceptible de perdurer ou si elle pourrait disparaître lors de la prochaine période de reporting en raison de fluctuations aléatoires.
Cette distinction est particulièrement importante lors de la prise de décisions concernant l’allocation des ressources. Supposons qu’une entreprise teste deux objets différents pour un e-mail et note que l’un génère 3 % de clics en plus que l’autre. Le test de signification statistique détermine si cette différence de 3 % est susceptible de se reproduire ou si elle pourrait se produire par hasard avec d’autres données. Si la différence est statistiquement significative avec un large échantillon, l’entreprise peut adopter en toute confiance l’objet le plus performant. Si ce n’est pas le cas, elle doit considérer que la différence observée pourrait ne pas refléter une véritable supériorité et soit collecter plus de données, soit traiter les deux options comme équivalentes.
Réduire les erreurs dans la prise de décision
La signification statistique aide les organisations à équilibrer deux types d’erreurs possibles dans les tests d’hypothèse : les erreurs de type I (faux positifs) et les erreurs de type II (faux négatifs). Une erreur de type I survient lorsque l’on conclut à tort qu’un effet existe alors qu’il n’existe pas – autrement dit, voir un schéma qui n’existe pas. Une erreur de type II correspond à l’incapacité de détecter un effet réel. Le seuil de signification (généralement 0,05) contrôle directement la probabilité de commettre une erreur de type I, la limitant à 5 % lorsque l’hypothèse nulle est vraie.
Type d’erreur
Définition
Impact commercial
Exemple
Erreur de type I (Faux positif)
Conclure qu’un effet existe alors que ce n’est pas le cas
Mettre en place des stratégies inefficaces, gaspiller des ressources
Adopter une tactique marketing qui semble fonctionner mais qui n’est en réalité qu’une variation aléatoire
Erreur de type II (Faux négatif)
Ne pas détecter un effet réel
Manquer des opportunités, conserver des processus inférieurs
Ne pas reconnaître qu’une optimisation réellement efficace fonctionne à cause d’un échantillon trop petit
Décision correcte
Identifier avec précision les effets réels ou leur absence
Allocation optimale des ressources, stratégie fondée sur les preuves
Déterminer correctement qu’une nouvelle structure de commissions améliore réellement la performance des recruteurs affiliés
En définissant à l’avance des seuils de signification avant l’analyse, les organisations établissent un cadre structuré qui prévient à la fois l’excès d’enthousiasme (agir sur des faux positifs) et un excès de scepticisme (manquer de véritables opportunités). Cette discipline est particulièrement précieuse dans l’affiliation, où les décisions concernant les commissions, les stratégies promotionnelles et le recrutement d’affiliés influent directement sur la rentabilité.
Favoriser la prise de décision éclairée dans tous les secteurs
La signification statistique offre la confiance nécessaire aux organisations pour investir massivement sur la base de résultats de recherche. Dans le développement pharmaceutique, les autorités de régulation exigent une signification statistique pour approuver de nouveaux médicaments, afin de garantir que les bénéfices constatés sont réels et non dus au hasard. Dans le marketing digital, la signification statistique valide que les résultats des tests A/B justifient la mise en place de nouveaux designs, campagnes e-mail ou stratégies publicitaires. En gestion de programme d’affiliation, elle confirme que les modifications apportées aux commissions, aux méthodes de suivi ou aux incitations des partenaires améliorent réellement la performance.
La standardisation des tests de signification statistique crée un langage commun entre secteurs et organisations. Lorsqu’un chercheur annonce que des résultats sont significatifs à p < 0,05, les professionnels du monde entier comprennent que la probabilité que le résultat soit dû au hasard est inférieure à 5 %. Cette standardisation permet des cadres de décision cohérents et la comparaison des résultats à travers différentes études, périodes et contextes. PostAffiliatePro s’appuie sur ces principes dans son moteur analytique, permettant aux gestionnaires d’affiliation d’identifier les partenaires et stratégies réellement performants, au lieu de réagir à de simples fluctuations passagères.
La distinction essentielle entre signification statistique et importance pratique
Un point clé à retenir est que la signification statistique diffère de l’importance pratique. Un résultat peut être statistiquement significatif – c’est-à-dire peu probable qu’il soit dû au hasard – tout en ayant un impact réel minime. Inversement, un résultat peut avoir une forte importance pratique mais ne pas atteindre la signification statistique à cause d’un échantillon trop petit ou d’une grande variabilité. Cette distinction est essentielle lors de l’interprétation des résultats de recherche et la prise de décisions commerciales.
Par exemple, imaginez une étude avec 10 000 participants montrant qu’une nouvelle stratégie de recrutement d’affiliés augmente les inscriptions de partenaires de 0,5 % avec une p-value de 0,03 (statistiquement significatif). Bien que le résultat soit significatif, l’impact réel pourrait être négligeable si le coût de la stratégie dépasse les revenus générés par ce 0,5 % supplémentaire. À l’inverse, une étude sur seulement 50 participants montrant une amélioration de 15 % de la rétention des affiliés pourrait ne pas atteindre la signification statistique à cause de la taille de l’échantillon, mais justifier tout de même une exploration approfondie du fait de son potentiel pratique.
Les facteurs clés influençant la signification statistique
Plusieurs facteurs influencent la probabilité qu’un résultat atteigne la signification statistique. La taille de l’échantillon est l’un des plus déterminants : des échantillons plus grands donnent des estimations plus fiables et augmentent la capacité à détecter des effets réels. Avec un petit échantillon, même des effets substantiels peuvent ne pas être significatifs à cause de la variabilité. Inversement, avec de très grands échantillons, même des effets minimes peuvent devenir significatifs, d’où la nécessité de considérer aussi l’importance pratique.
La taille de l’effet mesure l’ampleur de la différence entre les groupes ou la force de la relation entre variables. Les grands effets sont plus faciles à détecter et plus susceptibles d’être significatifs, tandis que les petits effets nécessitent plus de données. La variabilité des données est également cruciale : plus les données sont variables, plus il est difficile de détecter des effets, car le bruit masque le signal. Des techniques comme la standardisation ou la prise en compte des variables de confusion peuvent réduire cette variabilité et augmenter la détection d’effets réels. Les comparaisons multiples constituent un autre enjeu : réaliser de nombreux tests simultanément augmente fortement le risque d’obtenir au moins un faux positif, ce qui exige d’ajuster le seuil de signification pour préserver la rigueur globale.
Bonnes pratiques pour le reporting et l’interprétation de la signification statistique
Lorsqu’on communique des résultats statistiques, la clarté et la transparence sont essentielles. Un reporting efficace mentionne le test statistique utilisé, la p-value obtenue, le seuil choisi, la taille de l’échantillon, ainsi que la taille de l’effet. Ces informations permettent aux lecteurs d’évaluer la fiabilité et l’importance réelle des résultats. Les chercheurs doivent également discuter des limites, des variables de confusion potentielles et des hypothèses sous-jacentes à l’analyse. Les rapports de PostAffiliatePro illustrent cette approche en fournissant des métriques détaillées assorties d’intervalles de confiance et de tailles d’effet, permettant aux gestionnaires d’affiliation de prendre des décisions pleinement éclairées.
Une bonne pratique essentielle est d’éviter de se fier uniquement aux p-values comme unique critère de signification. Les pratiques statistiques modernes encouragent la présentation d’intervalles de confiance, qui offrent une fourchette plausible pour l’effet réel plutôt qu’une simple conclusion binaire. Les intervalles de confiance fournissent une information plus riche sur la précision des estimations et l’ampleur pratique des effets. Par exemple, un intervalle de confiance à 95 % pour une amélioration du taux de conversion pourrait aller de 2 % à 8 %, ce qui indique qu’il existe une amélioration significative, mais que son ampleur réelle reste incertaine. Cette information aide les décideurs à évaluer si le bénéfice potentiel justifie les coûts de mise en œuvre.
Éviter les idées reçues et les pièges courants
De nombreux malentendus concernant la signification statistique peuvent entraîner des interprétations erronées et de mauvaises décisions. L’une des idées reçues les plus répandues est de croire qu’un résultat significatif prouve que l’hypothèse alternative est vraie. En réalité, la signification statistique indique seulement que les données observées sont peu probables sous l’hypothèse nulle ; elle ne prouve ni la causalité, ni la vérité absolue. Une autre erreur fréquente est de penser qu’un résultat non significatif prouve l’absence d’effet. En fait, cela signifie simplement qu’il n’y a pas suffisamment de preuves pour rejeter l’hypothèse nulle, ce qui peut être dû à la taille de l’échantillon, à la variabilité ou à l’absence réelle d’effet.
La pratique du « p-hacking » – tester de multiples hypothèses jusqu’à obtenir un résultat significatif – est un écueil majeur qui augmente le taux de faux positifs. Lorsque de nombreux tests sont réalisés sans ajuster les seuils de signification, la probabilité d’obtenir un résultat significatif par hasard s’accroît fortement. Ce problème est particulièrement aigu lors d’analyses exploratoires où de nombreuses relations potentielles sont testées. La rigueur statistique exige soit de pré-spécifier les hypothèses avant l’analyse, soit d’ajuster les seuils de signification lors de comparaisons multiples (par exemple avec la correction de Bonferroni).
La signification statistique dans le contexte du marketing d’affiliation
Pour les gestionnaires de programmes d’affiliation, la signification statistique est un guide essentiel pour optimiser la performance et allouer efficacement les ressources. Lorsqu’on teste de nouvelles structures de commissions, des stratégies de recrutement ou des technologies de suivi, la signification statistique permet de savoir si les changements observés reflètent de véritables améliorations ou de simples fluctuations temporaires. La plateforme analytique de PostAffiliatePro intègre les tests de signification statistique à son cœur, permettant aux gestionnaires d’identifier avec certitude les affiliés les plus performants, de valider l’efficacité des évolutions du programme et de prendre des décisions éclairées quant à l’allocation des ressources.
Prenons le scénario où un manager d’affiliation met en place une nouvelle structure de commissions par palier et constate une augmentation de 8 % des gains moyens des affiliés le premier mois. Le test de signification statistique permet de déterminer si cette amélioration va probablement perdurer ou si elle risque de disparaître à mesure que le programme se stabilise. Si l’amélioration est significative statistiquement sur un échantillon représentatif d’affiliés, le manager peut conserver en toute confiance la nouvelle structure. Sinon, il doit soit collecter plus de données, soit vérifier si d’autres facteurs (saisonnalité, évolution du marché) expliquent l’amélioration apparente. Cette approche disciplinée prévient les erreurs coûteuses et garantit que les modifications apportées au programme améliorent réellement la performance.
La signification statistique demeure indispensable à l’analyse moderne des données et à la prise de décision. En fournissant un cadre objectif pour distinguer effets réels et variation aléatoire, elle permet aux organisations de prendre des décisions fondées sur des preuves. Comprendre ses principes, ses limites et sa bonne utilisation est essentiel pour toute personne travaillant avec des données, que ce soit en recherche, en analyse commerciale ou en gestion de programmes d’affiliation. À mesure que la donnée devient centrale dans la stratégie des organisations, la capacité à interpréter correctement la signification statistique devient un avantage concurrentiel décisif.
Prenez des décisions fondées sur les données en toute confiance
Les outils d’analyse avancés et de reporting de PostAffiliatePro vous permettent de suivre la performance des affiliés avec une rigueur statistique. Comprenez quelles stratégies marketing génèrent réellement des résultats et optimisez votre programme d’affiliation en vous appuyant sur des analyses de données fiables.
Comment la signification statistique est-elle utilisée ? Guide complet pour des décisions fondées sur les données
Découvrez comment la signification statistique permet de déterminer si les résultats sont réels ou dus au hasard. Comprenez les p-values, les tests d'hypothèses...
La signification statistique exprime la fiabilité des données mesurées, aidant les entreprises à distinguer les effets réels du hasard et à prendre des décision...