Comment identifier les robots d’indexation des moteurs de recherche ?
Découvrez comment identifier les robots d’indexation des moteurs de recherche grâce aux chaînes user-agent, aux adresses IP, aux schémas de requêtes et à l’analyse comportementale. Guide essentiel pour webmasters et développeurs.
Comment identifier les robots d’indexation des moteurs de recherche ?
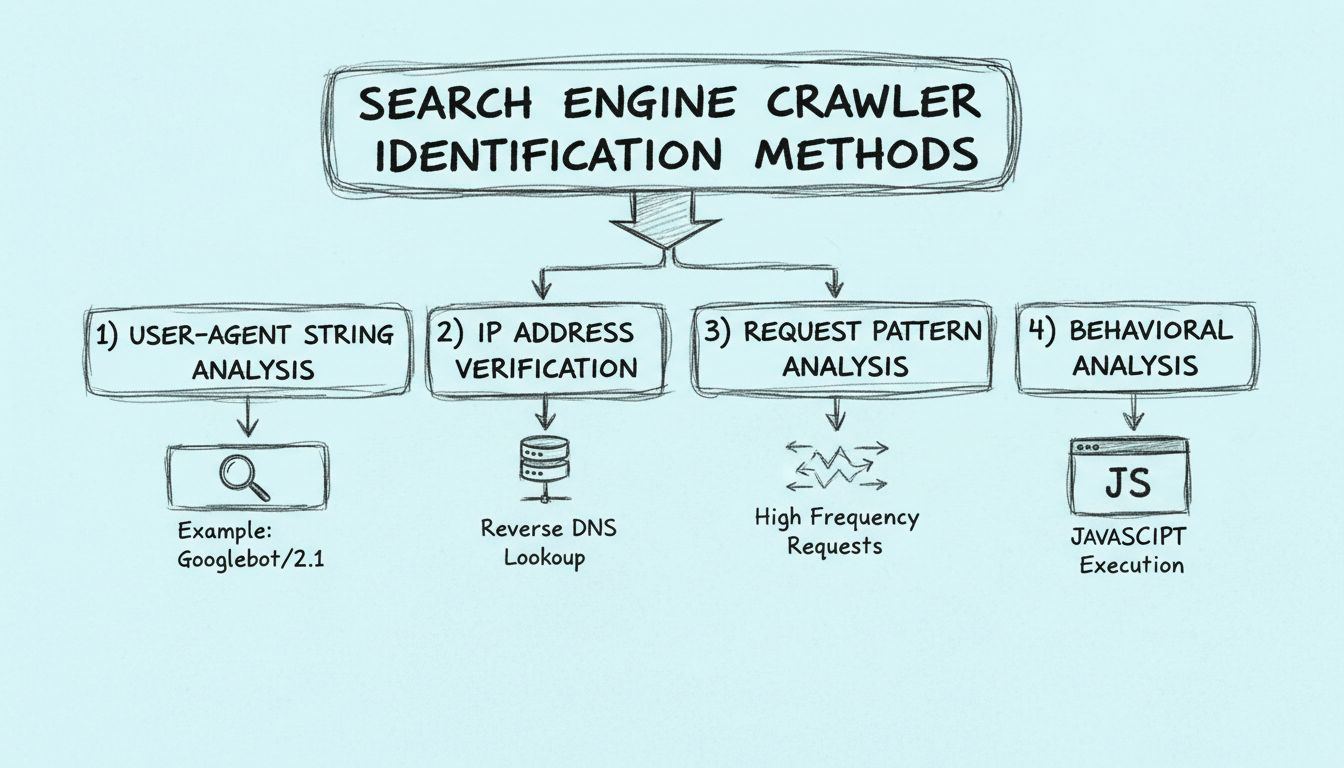
Les robots d’indexation des moteurs de recherche peuvent être identifiés par quatre méthodes principales : l’analyse de la chaîne user-agent dans les en-têtes HTTP, la vérification de l’adresse IP source et du nom d’hôte DNS inversé, la surveillance des schémas de requêtes pour détecter un accès à haute fréquence, et l’examen des caractéristiques comportementales comme la capacité à exécuter du JavaScript.
Comprendre l’identification des robots d’indexation des moteurs de recherche
Les robots d’indexation des moteurs de recherche sont des programmes automatisés qui parcourent systématiquement Internet afin de découvrir, analyser et indexer le contenu web. L’identification de ces robots est cruciale pour les webmasters, développeurs et marketeurs affiliés qui souhaitent comprendre les schémas de trafic de leur site et garantir un accès légitime des moteurs de recherche. Contrairement aux bots malveillants qui tentent d’extraire des données ou de lancer des attaques, les robots d’indexation légitimes tels que Googlebot, Bingbot et d’autres s’identifient par des marqueurs techniques spécifiques qui peuvent être vérifiés et authentifiés.
La capacité à distinguer les robots d’indexation légitimes des autres types de bots est devenue de plus en plus importante en 2025, à mesure que le trafic web augmente et que l’activité des bots se complexifie. Comprendre les méthodes d’identification vous aide à optimiser l’exploration de votre site, à protéger vos ressources contre les accès non autorisés et à garantir que vos systèmes de suivi d’affiliation distinguent avec précision le trafic organique des moteurs de recherche des autres sources. PostAffiliatePro propose des capacités d’analyse avancées qui vous aident à surveiller et catégoriser les sources de trafic avec précision, assurant ainsi à votre programme d’affiliation de collecter des données de performance fiables.
Méthode 1 : Analyse de la chaîne User-Agent
La méthode la plus simple pour identifier les robots d’indexation consiste à examiner la chaîne User-Agent dans l’en-tête de la requête HTTP. Chaque requête HTTP inclut un en-tête User-Agent qui identifie le client à l’origine de la requête, qu’il s’agisse d’un navigateur, d’une application mobile ou d’un robot. Les robots d’indexation légitimes incluent des identifiants distinctifs dans leur User-Agent, indiquant clairement leur origine et leur objectif. Par exemple, le robot de Google s’identifie comme “Googlebot/2.1 (+http://www.google.com/bot.html)”, tandis que celui de Microsoft Bing utilise “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)”.
Lorsque vous analysez les chaînes User-Agent, recherchez des schémas et des mots-clés spécifiques qui indiquent la présence de robots d’indexation légitimes. La chaîne User-Agent contient généralement le nom du robot, le numéro de version et un lien vers la documentation ou la page d’information du robot. Les robots légitimes des principaux moteurs de recherche comme Google, Bing, Yahoo et Yandex suivent des conventions de nommage cohérentes et fournissent des informations vérifiables sur leur objectif. Vous pouvez consigner ces chaînes User-Agent dans les journaux d’accès de votre serveur et les comparer aux identifiants de robots connus, maintenus par les moteurs de recherche et les organisations de sécurité.
Cependant, se fier uniquement aux chaînes User-Agent pour identifier les robots présente des limites. Les bots malveillants peuvent usurper les User-Agent pour se faire passer pour des robots légitimes, ce qui rend essentiel de combiner cette méthode à d’autres techniques de vérification. De plus, certains robots légitimes peuvent utiliser des chaînes User-Agent génériques ou modifiées dans certaines situations, donc le croisement avec d’autres méthodes d’identification fournit des résultats plus fiables.
Lancez votre programme d'affiliation aujourd'hui
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
Méthode 2 : Vérification de l’adresse IP et recherche DNS inversée
La seconde méthode essentielle pour identifier les robots d’indexation consiste à vérifier l’adresse IP source et à effectuer une recherche DNS inversée. Lorsqu’un robot effectue une requête sur votre serveur, elle provient d’une adresse IP spécifique que vous pouvez consigner et analyser. Les moteurs de recherche publient les plages d’adresses IP utilisées par leurs robots, permettant aux webmasters de vérifier si une requête provient réellement de l’infrastructure du moteur de recherche. Google, par exemple, maintient une liste complète des adresses IP utilisées par Googlebot et d’autres robots Google.
La recherche DNS inversée est une technique de vérification particulièrement efficace, consistant à interroger le système DNS pour déterminer le nom d’hôte associé à une adresse IP. Si vous effectuez une recherche inversée sur une adresse IP se prétendant être de Google, elle doit se résoudre à un nom d’hôte appartenant au domaine Google (par exemple, “crawl-66-249-64-1.googlebot.com”). Ce nom d’hôte peut ensuite être vérifié par une recherche DNS directe afin de confirmer que le nom d’hôte se résout à la même adresse IP, créant ainsi une chaîne de vérification bidirectionnelle. Ce processus rend extrêmement difficile l’usurpation d’identité d’un robot par des acteurs malveillants, car ils devraient contrôler à la fois l’adresse IP et les enregistrements DNS associés.
La documentation officielle de Google recommande cette méthode comme la plus fiable pour confirmer les requêtes de Googlebot. Le processus consiste à vérifier que le nom d’hôte DNS inversé correspond au modèle de domaine de Google puis à s’assurer, via une résolution DNS directe, que le nom d’hôte renvoie à la même adresse IP. Cette méthode est particulièrement précieuse pour les sites à fort trafic et les réseaux d’affiliation qui doivent garantir une attribution de trafic précise et éviter que l’activité de bots frauduleux ne soit comptabilisée comme trafic légitime des moteurs de recherche.
Méthode 3 : Analyse des schémas de requêtes et surveillance de la fréquence
L’analyse des schémas de requêtes fournit des informations précieuses sur le comportement des robots en étudiant la façon dont les requêtes sont réparties dans le temps et sur les ressources de votre site. Les robots d’indexation légitimes suivent des schémas prévisibles qui diffèrent fortement du comportement de navigation humaine ou de l’activité des bots malveillants. Les robots effectuent généralement des requêtes à intervalles réguliers, suivent un parcours logique à travers la structure d’URL de votre site, et respectent les directives de votre fichier robots.txt. En surveillant ces schémas, vous pouvez identifier les robots légitimes et les distinguer des activités suspectes.
Lors de l’analyse des schémas de requêtes, recherchez plusieurs caractéristiques clés indiquant un comportement de robot légitime. Premièrement, examinez la fréquence et la répartition des requêtes — les robots légitimes espaceraient généralement leurs requêtes pour ne pas surcharger votre serveur, souvent en suivant des algorithmes d’atténuation exponentielle ralentissant en cas d’erreurs HTTP 500 ou d’autres signes de stress serveur. Deuxièmement, analysez le schéma de parcours des URL — les robots légitimes suivent systématiquement les liens et respectent la structure du site, tandis que les bots malveillants effectuent souvent des requêtes aléatoires ou séquentielles vers des URL inexistantes ou non liées depuis votre site. Troisièmement, surveillez les types de ressources demandées — les robots d’indexation légitimes sollicitent généralement les pages HTML, les fichiers CSS et JavaScript nécessaires au rendu des pages, tout en évitant les requêtes inutiles vers des fichiers binaires ou des répertoires sensibles.
Vous pouvez mettre en place une surveillance des schémas de requêtes en analysant les journaux de votre serveur et en identifiant des groupes de requêtes partageant des caractéristiques communes. Des outils comme les plateformes d’analyse web et les logiciels d’analyse de logs serveur peuvent automatiser ce processus en signalant les schémas anormaux. Par exemple, si une seule adresse IP effectue 1 000 requêtes par minute vers différentes pages produits de manière séquentielle, il s’agit probablement d’un robot. En revanche, les robots d’indexation légitimes effectuent généralement des requêtes à une fréquence bien plus faible, espaçant souvent leurs requêtes de plusieurs secondes pour préserver les ressources serveur et éviter les mécanismes de limitation de débit.
Méthode 4 : Analyse comportementale et exécution de JavaScript
L’analyse comportementale consiste à observer la manière dont les robots interagissent avec le contenu et la technologie de votre site, fournissant ainsi des indices permettant de distinguer les robots d’indexation légitimes des autres types de bots. L’une des caractéristiques comportementales majeures est la capacité à exécuter du JavaScript. Les moteurs de recherche modernes comme Google rendent les pages à l’aide d’un navigateur sans interface (similaire à Chrome) pour exécuter le JavaScript et accéder au contenu généré dynamiquement. Cela signifie que les robots légitimes exécuteront le code JavaScript de vos pages, alors que de nombreux bots malveillants ou extracteurs simples ne peuvent pas ou ne le font pas.
Vous pouvez détecter l’exécution de JavaScript en intégrant du code de suivi qui ne s’exécute que si JavaScript est activé et fonctionnel. Si une requête accède à votre page sans déclencher le suivi dépendant de JavaScript ou sans charger le contenu dynamique, cela indique que le demandeur n’est peut-être pas un robot d’indexation moderne. Par ailleurs, les robots d’indexation légitimes chargent généralement toutes les ressources nécessaires au rendu complet d’une page, y compris images, feuilles de style et fichiers JavaScript, alors que les bots simples se limitent souvent au fichier HTML sans charger les ressources associées.
Un autre indicateur comportemental important est la manière dont les robots gèrent les éléments interactifs et les soumissions de formulaires. Les robots d’indexation légitimes ne soumettent pas de formulaires, ne cliquent pas sur des boutons et n’interagissent pas avec le contenu dynamique d’une façon qui pourrait générer des effets indésirables comme passer des commandes ou modifier des données. Leur objectif est de lire et d’analyser le contenu, non d’interagir avec lui. Les bots malveillants, en revanche, tentent souvent d’interagir avec les formulaires, de soumettre des données ou de déclencher des actions susceptibles de nuire à votre site ou de voler des informations. En surveillant ces schémas comportementaux, vous pouvez identifier les requêtes cherchant à réaliser des interactions non autorisées et les distinguer de l’activité des robots légitimes.
Workflow complet d’identification des robots d’indexation
L’approche la plus efficace pour identifier les robots consiste à combiner ces quatre méthodes dans un workflow de vérification complet. Plutôt que de s’appuyer sur une seule méthode, la mise en place d’un système de vérification en couches offre une protection robuste contre les robots usurpés et garantit une attribution de trafic précise. Commencez par enregistrer la chaîne User-Agent et l’adresse IP de chaque requête, puis recoupez ces informations avec les bases de robots connus tenues à jour par les moteurs de recherche et les organismes de sécurité. Ensuite, effectuez une recherche DNS inversée pour vérifier que le nom d’hôte de l’adresse IP correspond au domaine revendiqué du moteur de recherche. Enfin, analysez le schéma de requêtes et les caractéristiques comportementales pour vous assurer que l’activité correspond à celle d’un robot légitime.
Cette approche multicouche est particulièrement importante pour les réseaux d’affiliation et les plateformes de marketing à la performance comme PostAffiliatePro, où l’attribution précise du trafic influence directement les calculs de commission et l’intégrité du programme. En mettant en œuvre une identification complète des robots, vous pouvez garantir que vos systèmes de suivi d’affiliation distinguent correctement le trafic légitime des moteurs de recherche, le trafic publicitaire payant et le trafic utilisateur organique. Cette précision permet une meilleure analyse des performances, un calcul du ROI plus fiable et une détection accrue des fraudes.
Bonnes pratiques pour l’identification des robots d’indexation en 2025
L’infrastructure web moderne exige des systèmes d’identification des robots sophistiqués, capables de gérer la complexité croissante du trafic web. Tout d’abord, maintenez à jour une liste des adresses IP et User-Agent de robots légitimes en vous abonnant aux notifications officielles des principaux moteurs de recherche. Google, Bing et d’autres publient des mises à jour lorsqu’ils ajoutent de nouveaux robots ou modifient leur infrastructure ; rester informé de ces changements garantit la pertinence de vos systèmes d’identification. Ensuite, mettez en place des logs côté serveur qui enregistrent toutes les métadonnées pertinentes des requêtes, y compris User-Agent, adresses IP, horodatages et ressources demandées. Ces données constituent la base de l’analyse des schémas et de la surveillance comportementale.
Troisièmement, envisagez de mettre en œuvre une API ou un service de vérification des robots qui valide automatiquement l’identité des robots en temps réel. De nombreuses plateformes de sécurité et d’analyse proposent désormais des services d’identification des robots, maintenant à jour des bases de données de robots légitimes et permettant de vérifier les requêtes en temps réel. Quatrièmement, définissez des politiques claires pour la gestion des activités de robots non identifiés ou suspects. Vous pouvez choisir de servir ces requêtes normalement tout en les consignant pour analyse, ou de mettre en place une limitation de débit pour prévenir l’épuisement des ressources. Enfin, révisez et mettez régulièrement à jour vos règles et seuils d’identification des robots en fonction des schémas de trafic observés et des nouvelles menaces. Le paysage de l’indexation web continue d’évoluer, et vos systèmes d’identification doivent s’adapter en conséquence pour conserver leur efficacité.
Conclusion
Identifier les robots d’indexation des moteurs de recherche nécessite une compréhension approfondie de plusieurs méthodes de vérification et la capacité à les combiner dans un système de détection efficace. En analysant les chaînes User-Agent, en vérifiant les adresses IP par recherches DNS inversées, en surveillant les schémas de requêtes et en examinant les caractéristiques comportementales, vous pouvez distinguer de manière fiable les robots d’indexation légitimes des autres bots et sources de trafic. Cette capacité est essentielle pour les webmasters, développeurs et marketeurs affiliés, qui doivent comprendre l’origine de leur trafic et garantir un suivi de performance précis. Les capacités avancées d’analyse et de surveillance de PostAffiliatePro vous aident à mettre en œuvre efficacement ces méthodes d’identification, assurant à votre programme d’affiliation de collecter des données fiables et de préserver son intégrité dans un écosystème numérique de plus en plus complexe.
Optimisez votre programme d’affiliation avec PostAffiliatePro
PostAffiliatePro est le logiciel de gestion d’affiliation leader qui vous aide à suivre, gérer et optimiser votre réseau d’affiliés avec précision. Identifiez les sources de trafic légitimes et maximisez la performance de votre programme d’affiliation grâce à des analyses avancées et une surveillance en temps réel.
Les crawlers et leur rôle dans le classement des moteurs de recherche
Les crawlers accumulent des données et des informations sur Internet en visitant des sites web et en lisant leurs pages. Découvrez-en plus à leur sujet.
Qu'est-ce que le Google Spider ? Guide complet sur l’exploration de Googlebot
Découvrez ce qu’est le Google Spider (Googlebot), comment il explore et indexe les sites web, et pourquoi il est essentiel pour le SEO. Apprenez à optimiser vot...
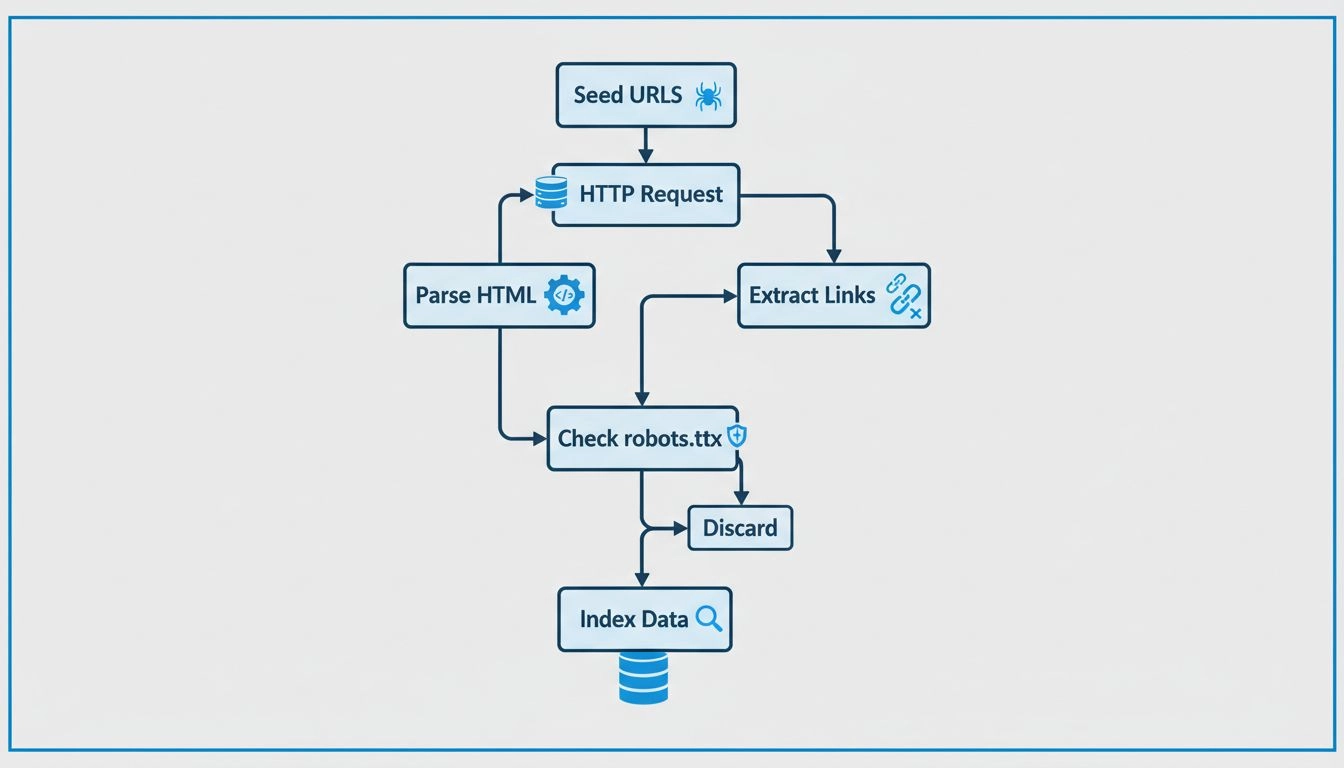
Comment fonctionnent les crawlers web ? Guide technique complet
Découvrez comment fonctionnent les crawlers web, des URLs sources à l'indexation. Comprenez le processus technique, les types de crawlers, les règles robots.txt...
11 min de lecture
Vous serez entre de bonnes mains !
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.