

Comment fonctionnent les crawlers web ? Guide technique complet
Découvrez comment fonctionnent les crawlers web, des URLs sources à l'indexation. Comprenez le processus technique, les types de crawlers, les règles robots.txt...
11 min de lecture

Get your
33% off
+ free AI Agent
Les crawlers, également appelés spiders ou bots, parcourent et indexent systématiquement Internet, permettant aux moteurs de recherche de comprendre et de classer les pages web pour des requêtes pertinentes.
Les crawlers, également appelés spiders ou bots, sont des logiciels automatisés sophistiqués conçus pour parcourir et indexer de manière systématique l’immense étendue d’Internet. Leur fonction principale est d’aider les moteurs de recherche à comprendre, catégoriser et classer les pages web en fonction de leur pertinence et de leur contenu. Ce processus est essentiel pour permettre aux moteurs de recherche de fournir des résultats précis aux utilisateurs. En scannant continuellement les pages web, les crawlers construisent un index complet que des moteurs de recherche comme Google utilisent pour livrer des résultats de recherche précis et pertinents.
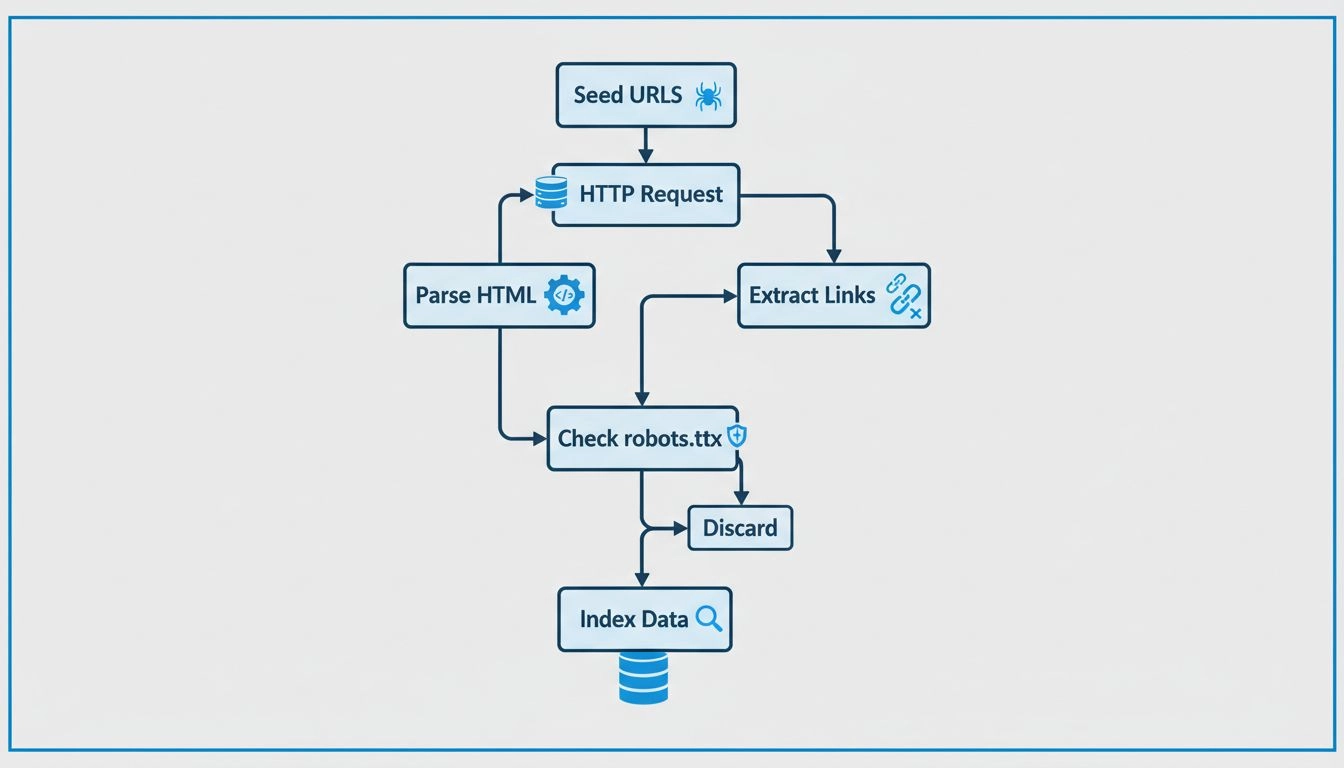
Les robots d’exploration web représentent en quelque sorte les yeux et les oreilles des moteurs de recherche, leur permettant de voir le contenu de chaque page web, d’en comprendre la teneur et de décider où la placer dans l’index. Ils commencent avec une liste d’URL connues et parcourent méthodiquement chaque page, analysant le contenu, identifiant les liens et les ajoutant à leur file d’attente pour un crawl futur. Ce processus itératif permet aux crawlers de cartographier la structure de l’ensemble du web, à l’image d’un bibliothécaire numérique qui classe les livres.
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
Les crawlers fonctionnent en démarrant avec une liste initiale d’URL, qu’ils visitent et inspectent. En analysant ces pages web, ils identifient des liens vers d’autres pages et les ajoutent à leur file d’attente pour un crawl ultérieur. Ce processus leur permet de cartographier la structure du web, en suivant les liens de page en page, à la manière d’un bibliothécaire numérique qui classe les livres. Le contenu de chaque page, y compris le texte, les images et les balises meta, est analysé et stocké dans un vaste index. Cet index sert de base aux moteurs de recherche pour retrouver les informations pertinentes en réponse aux requêtes des utilisateurs.
Les robots d’exploration web consultent le fichier robots.txt de chaque page web qu’ils visitent. Ce fichier fournit des règles indiquant quelles pages doivent être explorées et lesquelles doivent être ignorées. Après avoir vérifié ces règles, les crawlers poursuivent la navigation sur la page web en suivant les liens hypertextes selon des politiques prédéfinies, comme le nombre de liens pointant vers une page ou son autorité. Ces politiques aident à prioriser l’exploration des pages importantes ou pertinentes afin qu’elles soient indexées rapidement.
Au fur et à mesure de leur exploration, ces bots stockent le contenu et les métadonnées de chaque page. Ces informations sont cruciales pour permettre aux moteurs de recherche de déterminer la pertinence d’une page pour la requête d’un utilisateur. Les données collectées sont ensuite indexées, ce qui permet au moteur de recherche de retrouver et de classer rapidement les pages lors d’une recherche.
Pour les marketeurs affiliés , comprendre le fonctionnement des crawlers est essentiel pour optimiser leurs sites web et améliorer leur positionnement dans les moteurs de recherche. Un SEO efficace consiste à structurer le contenu du site de manière à ce qu’il soit facilement accessible et compréhensible pour ces bots. Les pratiques SEO importantes comprennent :
Soyez le premier à connaître les nouvelles fonctionnalités et mises à jour.
Dans le contexte du marketing d’affiliation , les crawlers jouent un rôle particulier. Voici quelques éléments clés à considérer :
Les marketeurs affiliés peuvent utiliser des outils comme Google Search Console pour obtenir des informations sur la façon dont les crawlers interagissent avec leurs sites. Ces outils fournissent des données sur les erreurs de crawl, la soumission de sitemaps et d’autres indicateurs, permettant ainsi d’améliorer la crawlabilité et l’indexation du site. Surveiller l’activité de crawl aide à identifier les problèmes qui pourraient nuire à l’indexation, permettant ainsi des corrections rapides.
Un contenu indexé est essentiel pour la visibilité dans les résultats des moteurs de recherche. Sans indexation, une page web n’apparaîtra pas dans les résultats de recherche, quelle que soit sa pertinence pour une requête. Pour les affiliés , s’assurer que leur contenu est bien indexé est crucial pour générer du trafic organique et des conversions. Une indexation correcte garantit que le contenu peut être découvert et classé de manière appropriée.
Le SEO technique consiste à optimiser l’infrastructure du site pour faciliter un crawl et une indexation efficaces. Cela comprend :
Données structurées : La mise en place de données structurées aide les crawlers à comprendre le contexte du contenu, augmentant ainsi les chances du site d’apparaître dans les résultats enrichis. Les données structurées fournissent des informations supplémentaires qui peuvent améliorer la visibilité dans les recherches.
Vitesse et performance du site : Les sites qui se chargent rapidement sont privilégiés par les crawlers et offrent une expérience utilisateur positive. Une meilleure vitesse du site peut entraîner un meilleur classement et une augmentation du trafic.
Pages sans erreur : Identifier et corriger les erreurs de crawl garantit que toutes les pages importantes sont accessibles et indexables. Des audits réguliers permettent de maintenir la santé du site et d’améliorer les performances SEO.

Découvrez comment comprendre et optimiser pour les crawlers peut augmenter la visibilité de votre site web et améliorer son classement dans les moteurs de recherche.
Découvrez comment fonctionnent les crawlers web, des URLs sources à l'indexation. Comprenez le processus technique, les types de crawlers, les règles robots.txt...

Découvrez ce qu’est le Google Spider (Googlebot), comment il explore et indexe les sites web, et pourquoi il est essentiel pour le SEO. Apprenez à optimiser vot...
L'indexation est un processus par lequel une page web est trouvée par les robots d'exploration. Des signaux clés sont détectés et toutes les données sont suivie...
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.
Consentement aux Cookies
Nous utilisons des cookies pour améliorer votre expérience de navigation et analyser notre trafic. See our privacy policy.