Comment fonctionnent les liens de site web ? Guide complet sur les URL et la navigation web
Découvrez comment fonctionnent les liens de site web, comprenez la structure des URL, la résolution DNS et le processus technique derrière la navigation web. Guide expert pour 2025.
Comment fonctionnent les liens de site web ?
Les liens de site web fonctionnent en utilisant des URL (Uniform Resource Locators) qui dirigent les navigateurs vers des pages web spécifiques. Lorsque vous cliquez sur un lien ou saisissez une URL, votre navigateur utilise le DNS pour traduire le nom de domaine en une adresse IP, puis se connecte au serveur et récupère le contenu de la page demandée.
Comprendre les liens de site web et les URL
Les liens de site web sont les éléments fondamentaux de la navigation sur Internet, permettant aux utilisateurs de passer facilement d’une page à l’autre et d’accéder à des ressources à travers le web. Un lien de site web est essentiellement une URL (Uniform Resource Locator) qui dirige un utilisateur vers une page précise d’un site. Pour qu’un lien fonctionne correctement, l’URL doit être saisie dans un navigateur web exactement telle qu’elle apparaît, ou être consultée via un hyperlien. Le fonctionnement des liens de site web implique plusieurs couches technologiques qui coopèrent en parfaite harmonie, de la barre d’adresse de votre navigateur jusqu’aux serveurs distants hébergeant le contenu recherché.
Comprendre le fonctionnement des liens de site web est essentiel pour toute personne impliquée dans le développement web, le marketing digital ou l’affiliation. Lorsque vous cliquez sur un lien ou saisissez manuellement une URL dans la barre d’adresse de votre navigateur, une série d’événements complexes se déroulent en arrière-plan. Votre navigateur doit identifier le protocole utilisé, localiser le serveur approprié via le système DNS (Domain Name System), demander la ressource spécifique, puis enfin afficher le contenu. Ce processus complet prend généralement quelques secondes, mais implique de nombreux ordinateurs et systèmes communiquant ensemble à travers Internet.
L’anatomie d’une URL : décomposition de la structure d’un lien de site web
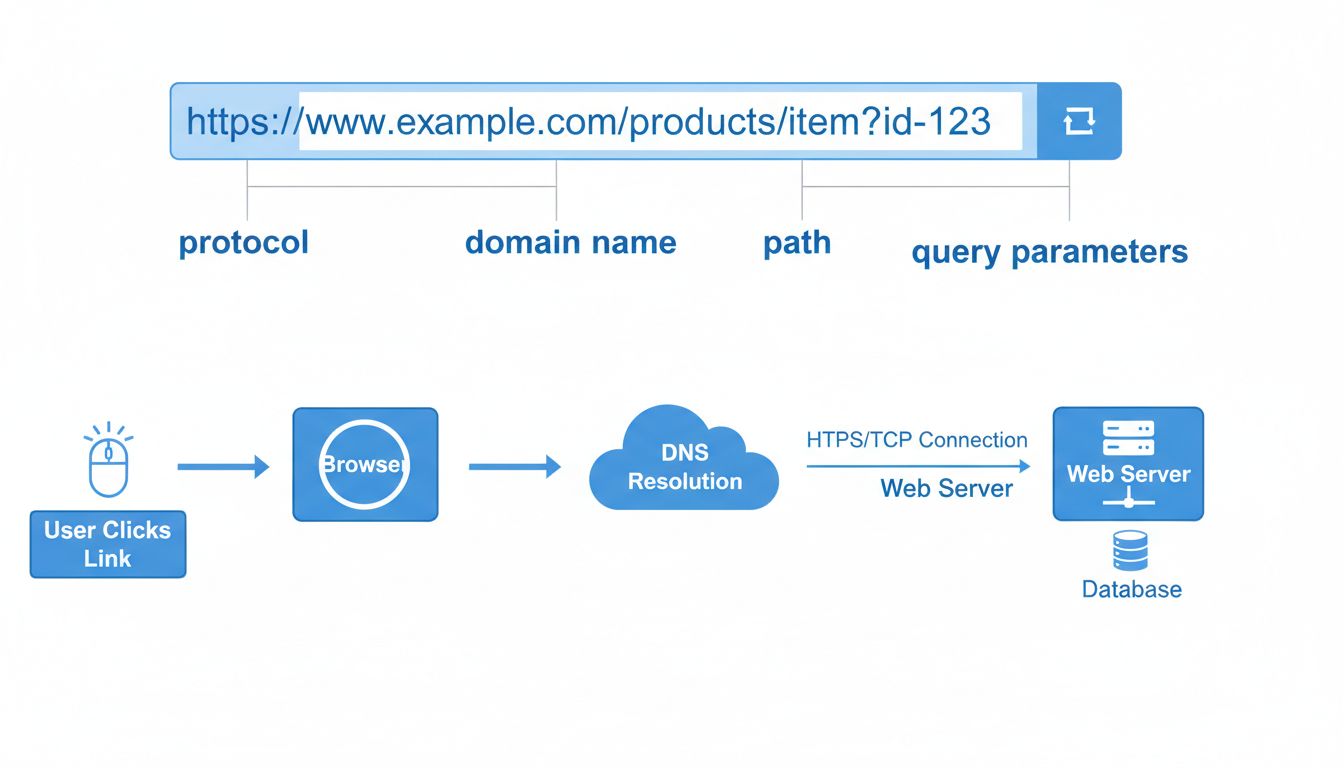
Une URL se compose de plusieurs éléments distincts, chacun jouant un rôle spécifique pour diriger votre navigateur vers la bonne ressource. Comprendre ces éléments est crucial pour saisir le fonctionnement des liens de site web et l’importance de la précision lors de la saisie d’une URL. La structure de base d’une URL suit ce schéma : protocole://sous-domaine.domaine.extension/chemin?paramètres#fragment. Chacun de ces éléments joue un rôle essentiel durant la navigation, et des éléments manquants ou incorrects peuvent entraîner des liens cassés ou des échecs de connexion.
Élément de l’URL
Exemple
Rôle
Protocole
https://
Spécifie la méthode de communication (HTTP ou HTTPS)
Sous-domaine
www
Organise différentes sections d’un site
Nom de domaine
exemple
L’identifiant unique du site web
Extension (TLD)
.com
Domaine de premier niveau indiquant le type/pays du site
Chemin
/produits/article
Spécifie l’emplacement exact de la ressource
Paramètres
?id=123&color=blue
Transmet des données supplémentaires au serveur
Fragment
#section-2
Pointe vers une section précise d’une page
Le protocole est le premier élément clé de toute URL. HTTPS (Hypertext Transfer Protocol Secure) est devenu la norme pour les sites modernes, remplaçant l’ancien protocole HTTP. HTTPS chiffre les données transmises entre votre navigateur et le serveur, protégeant ainsi les informations sensibles comme les mots de passe et numéros de carte bancaire contre toute interception. Lorsque vous voyez une icône de cadenas dans la barre d’adresse de votre navigateur, cela indique que la connexion est sécurisée et chiffrée. Cette couche de sécurité est essentielle pour les sites e-commerce, les plateformes bancaires, et tout site traitant des données personnelles ou financières.
Le nom de domaine est la partie la plus reconnaissable d’une URL et sert d’identifiant unique au site. Il se compose d’un domaine de second niveau (le nom choisi, comme « exemple ») et d’un domaine de premier niveau ou TLD (comme .com, .org ou .net). Le sous-domaine, généralement « www », précède le nom de domaine et permet d’organiser différentes sections du site. Certains sites utilisent des sous-domaines personnalisés comme « blog.exemple.com » ou « support.exemple.com » pour séparer différentes zones fonctionnelles. L’élément chemin précise l’emplacement exact d’une ressource sur le serveur, utilisant des barres obliques pour délimiter la structure des dossiers, à l’image de l’organisation des fichiers sur votre ordinateur.
Lancez votre programme d'affiliation aujourd'hui
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
Comment fonctionnent les liens de site web : le processus étape par étape
Lorsque vous cliquez sur un hyperlien ou saisissez une URL dans la barre d’adresse de votre navigateur, un processus sophistiqué se met en marche, impliquant plusieurs systèmes travaillant ensemble. Comprendre ce processus permet de saisir pourquoi les liens fonctionnent comme ils le font et pourquoi certaines erreurs peuvent survenir. Tout le parcours, du clic jusqu’à l’affichage de la page web, s’effectue généralement en quelques secondes, mais comprend plusieurs étapes distinctes qui doivent s’enchaîner sans erreur.
Étape 1 : Action de l’utilisateur et analyse de l’URL – Le processus commence lorsque vous cliquez sur un lien ou saisissez manuellement une URL dans la barre d’adresse de votre navigateur. Celui-ci analyse immédiatement l’URL, la découpant en ses différentes parties : protocole, nom de domaine, chemin, paramètres et fragments. Cette étape d’analyse est cruciale car le navigateur doit comprendre chaque composant pour savoir comment procéder. Si l’URL contient des erreurs de syntaxe ou des caractères invalides, le navigateur peut la rejeter ou essayer de la corriger automatiquement.
Étape 2 : Identification du protocole – Le navigateur examine le protocole spécifié dans l’URL (généralement HTTPS ou HTTP) pour déterminer comment établir la connexion avec le serveur. Le protocole définit les règles de communication entre votre navigateur et le serveur web. Les connexions HTTPS nécessitent des échanges de sécurité supplémentaires pour établir un tunnel chiffré, tandis que les connexions HTTP sont plus simples mais moins sécurisées. Les navigateurs modernes préviennent de plus en plus les utilisateurs lorsqu’ils visitent des sites HTTP, encourageant l’adoption généralisée de HTTPS.
Étape 3 : Résolution DNS – Il s’agit sans doute de l’étape la plus cruciale. Le navigateur doit traduire le nom de domaine lisible par l’humain (comme www.exemple.com
) en une adresse IP numérique compréhensible par les ordinateurs. Cette traduction s’effectue via le système de noms de domaine (DNS), un réseau distribué de serveurs qui maintient une immense base de données de noms de domaine et de leurs adresses IP respectives. Votre navigateur envoie une requête DNS à un résolveur DNS, qui parcourt la hiérarchie DNS pour trouver le serveur faisant autorité sur le domaine. Une fois trouvé, le résolveur récupère l’adresse IP et la transmet à votre navigateur. Ce processus prend généralement quelques millisecondes mais est essentiel pour établir la connexion.
Étape 4 : Connexion au serveur – Muni de l’adresse IP, votre navigateur établit une connexion avec le serveur web hébergeant le site. Pour une connexion HTTPS, cela implique une poignée de main TLS (Transport Layer Security) où navigateur et serveur échangent des clés cryptographiques pour établir une connexion sécurisée et chiffrée. Cette poignée de main vérifie l’identité du serveur via des certificats numériques et garantit que toute communication ultérieure sera chiffrée. Pour HTTP, le navigateur établit simplement une connexion TCP sur le port 80 du serveur (ou sur le port 443 pour HTTPS).
Étape 5 : Requête HTTP – Une fois la connexion établie, votre navigateur envoie une requête HTTP au serveur, spécifiant la ressource qu’il souhaite obtenir. Cette requête inclut le chemin indiqué dans l’URL, les paramètres ou chaînes de requête, ainsi que des en-têtes supplémentaires contenant des informations sur le navigateur, la langue préférée et d’autres métadonnées. Le serveur reçoit cette requête et la traite, déterminant quel fichier ou quelle ressource envoyer à votre navigateur.
Étape 6 : Réponse du serveur – Le serveur web traite la requête et renvoie une réponse HTTP contenant la ressource demandée. Cette réponse inclut un code d’état (comme 200 pour succès, 404 pour non trouvé, ou 500 pour erreur serveur), des en-têtes de réponse contenant des métadonnées sur le contenu, et le contenu lui-même (HTML, CSS, JavaScript, images, etc.). Le serveur peut également définir des cookies ou d’autres informations de suivi dans les en-têtes de la réponse.
Étape 7 : Rendu du contenu – Votre navigateur reçoit la réponse et commence à afficher le contenu. Il analyse le HTML pour comprendre la structure de la page, applique le style CSS pour mettre en forme le contenu, et exécute le JavaScript pour ajouter de l’interactivité. Si la page référence des ressources externes comme des images, feuilles de style ou scripts, votre navigateur effectue des requêtes supplémentaires pour récupérer ces ressources. Ce processus continue jusqu’à ce que toutes les ressources soient chargées et que la page soit entièrement affichée et interactive.
Résolution DNS : le moteur caché derrière les liens de site web
Le système de noms de domaine (DNS) est l’infrastructure invisible qui permet aux liens de site web de fonctionner en traduisant les noms de domaine en adresses IP. Sans DNS, les utilisateurs devraient mémoriser des adresses IP numériques complexes au lieu de noms de domaine simples comme « exemple.com ». Le DNS fonctionne comme un système hiérarchique et distribué comportant plusieurs couches de serveurs qui coopèrent pour résoudre les noms de domaine. Lorsque vous saisissez une URL dans votre navigateur, la résolution DNS démarre immédiatement et votre navigateur ne peut pas continuer tant qu’il n’a pas reçu l’adresse IP du domaine.
Le processus de résolution DNS fait intervenir plusieurs types de serveurs. Votre navigateur contacte d’abord un résolveur récursif, généralement fourni par votre fournisseur d’accès Internet (FAI) ou un service DNS public comme Google DNS ou Cloudflare DNS. Ce résolveur est chargé de trouver la réponse à votre requête DNS en consultant d’autres serveurs si nécessaire. S’il ne possède pas déjà la réponse en cache, il contacte un serveur racine, qui l’oriente vers le serveur de noms du domaine de premier niveau (TLD) approprié. Ce dernier oriente alors le résolveur vers le serveur faisant autorité pour le domaine spécifique, qui fournit enfin l’adresse IP. Ce processus, appelé récursivité DNS, se déroule de façon transparente et s’effectue en général en quelques millisecondes.
Le cache DNS joue un rôle crucial pour rendre les liens de site web efficaces. Lorsqu’un résolveur DNS obtient une adresse IP pour un domaine, il conserve cette information en cache pendant une durée définie par la valeur TTL (Time To Live) du domaine. Ce mécanisme évite d’effectuer une recherche DNS complète à chaque visite d’un site, ce qui accélère nettement la connexion. Votre navigateur conserve également son propre cache DNS, tout comme les FAI et d’autres résolveurs DNS à travers Internet. Ce système de cache multi-niveaux garantit que les sites populaires sont accessibles rapidement sans solliciter sans cesse les serveurs faisant autorité.
Rejoignez notre newsletter
Soyez le premier à connaître les nouvelles fonctionnalités et mises à jour.
HTTP et HTTPS : les protocoles qui alimentent les liens de site web
Le protocole spécifié au début d’une URL détermine la façon dont votre navigateur communique avec le serveur web. HTTP (Hypertext Transfer Protocol) était le protocole d’origine pour la communication sur le web, mais il transmettait les données en clair, sans chiffrement. Cela signifiait que toute personne interceptant le trafic réseau pouvait lire des informations sensibles, comme des mots de passe ou des numéros de carte bancaire. HTTPS (Hypertext Transfer Protocol Secure) corrige cette vulnérabilité en ajoutant une couche de chiffrement via des certificats SSL/TLS (Secure Sockets Layer/Transport Layer Security).
Lorsque vous visitez un site en HTTPS, votre navigateur et le serveur effectuent une poignée de main TLS pour établir une connexion chiffrée. Pendant cette étape, le serveur présente un certificat numérique qui prouve son identité et contient une clé publique. Votre navigateur vérifie l’authenticité du certificat en le comparant à une liste d’autorités de certification de confiance. Une fois vérifié, navigateur et serveur utilisent la clé publique pour établir une clé de chiffrement partagée, qui servira ensuite à chiffrer toutes les communications. Ce chiffrement garantit que même si quelqu’un intercepte le trafic réseau, il ne pourra pas lire les données transmises.
La différence entre HTTP et HTTPS ne concerne pas seulement la sécurité ; elle influence aussi le classement dans les moteurs de recherche et la confiance des utilisateurs. Google et d’autres moteurs de recherche privilégient les sites HTTPS dans leurs résultats, et les navigateurs modernes affichent des avertissements lorsque les utilisateurs accèdent à des sites HTTP. Les utilisateurs ont pris l’habitude de rechercher l’icône de cadenas dans la barre d’adresse comme signe de connexion sécurisée, et beaucoup quittent un site dès qu’ils voient des alertes de sécurité. Pour toutes ces raisons, HTTPS est devenu la norme pour l’ensemble des sites web, et pas seulement ceux manipulant des données sensibles.
Paramètres d’URL et chaînes de requête : ajouter des fonctionnalités aux liens
Les paramètres d’URL, aussi appelés chaînes de requête, permettent aux sites de transmettre des informations supplémentaires au serveur via l’URL elle-même. Ces paramètres apparaissent après un point d’interrogation (?) dans l’URL et se composent de paires clé-valeur séparées par des esperluettes (&). Par exemple, une URL de recherche peut ressembler à https://www.exemple.com/recherche?q=liens+site+web&categorie=technologie&tri=pertinence. Chaque paramètre fournit des informations spécifiques utilisées par le serveur pour personnaliser la réponse.
Les paramètres d’URL remplissent de nombreuses fonctions importantes dans le fonctionnement des liens de site web. Les moteurs de recherche les utilisent pour suivre les requêtes et filtrer les résultats. Les sites e-commerce les utilisent pour filtrer les produits par catégorie, gamme de prix ou autres attributs. Les plateformes d’analytique les emploient (appelés paramètres UTM) pour suivre la provenance et l’efficacité des campagnes marketing. Les paramètres de pagination permettent aux sites d’afficher de grands ensembles de données sur plusieurs pages. Sans les paramètres d’URL, les sites seraient beaucoup moins flexibles et puissants, incapables de personnaliser le contenu ou de suivre efficacement le comportement des utilisateurs.
Cependant, les paramètres d’URL posent aussi des défis pour le référencement naturel et l’expérience utilisateur. Les moteurs de recherche peuvent considérer les URL avec différents paramètres comme des pages distinctes, créant potentiellement des problèmes de contenu dupliqué. Les longues URL avec de nombreux paramètres sont difficiles à lire et à partager. Pour ces raisons, les pratiques modernes de développement web privilégient souvent des structures d’URL plus propres, utilisant des chemins plutôt que des paramètres lorsque cela est possible. Par exemple, au lieu de exemple.com/produits?categorie=chaussures, une structure plus claire serait exemple.com/produits/chaussures. Cependant, les paramètres restent essentiels pour le contenu dynamique et le suivi.
Erreurs courantes d’URL et comment les corriger
Comprendre le fonctionnement des liens de site web, c’est aussi comprendre ce qui peut mal tourner. L’erreur la plus fréquente est le 404 Not Found, qui survient lorsque le serveur ne trouve pas la ressource demandée à l’URL indiquée. Cela peut arriver si une page a été supprimée, déplacée vers une autre URL, ou si l’URL contient une faute de frappe. Parmi les autres erreurs courantes, on retrouve 403 Forbidden (accès non autorisé à la ressource), 500 Internal Server Error (problème interne au serveur), et 502 Bad Gateway (le serveur reçoit une réponse invalide d’un serveur en amont).
Lorsque vous rencontrez un lien cassé, plusieurs étapes de dépannage peuvent aider. Commencez par vérifier attentivement l’URL à la recherche de fautes de frappe ou de majuscules incorrectes. Les URL sont sensibles à la casse, ainsi Example.com et example.com peuvent être traités différemment par certains serveurs. Si l’URL semble correcte, essayez de supprimer le chemin après le nom de domaine pour voir si le site principal est accessible. Si le site principal fonctionne mais que la page spécifique non, il se peut que celle-ci ait été déplacée ou supprimée. Dans ce cas, vous pouvez rechercher le contenu via un moteur de recherche, qui peut vous diriger vers la nouvelle URL ou une version archivée.
Les propriétaires de sites peuvent éviter les liens cassés en mettant en place des redirections appropriées lors de changements d’URL. Une redirection 301 (redirection permanente) indique aux moteurs de recherche et aux navigateurs qu’une page a été déplacée définitivement, ce qui préserve le référencement et redirige automatiquement les utilisateurs. Une redirection 302 (temporaire) signale un déplacement temporaire et ne transmet pas l’autorité du référencement. En appliquant stratégiquement ces redirections, les propriétaires de sites maintiennent l’expérience utilisateur et le référencement, même lors de restructurations importantes.
Bonnes pratiques d’URL pour le développement web et le SEO
Créer des URL efficaces nécessite de comprendre le fonctionnement des liens de site web et de prendre en compte à la fois des aspects techniques et d’expérience utilisateur. Les URL doivent être descriptives et contenir des mots-clés pertinents indiquant le contenu de la page. Par exemple, exemple.com/blog/comment-optimiser-liens-site-web est bien plus informatif que exemple.com/page123. Des URL descriptives aident les utilisateurs et les moteurs de recherche à anticiper le contenu, améliorent le taux de clics dans les résultats et facilitent le partage sur les réseaux sociaux.
Les URL doivent également rester aussi courtes que possible tout en restant explicites. Les URL longues sont difficiles à saisir, à mémoriser et à partager. Elles peuvent aussi être tronquées dans les résultats de recherche ou les publications sur les réseaux sociaux, ce qui les rend moins efficaces pour le marketing. Utiliser des tirets pour séparer les mots dans les URL est préférable aux underscores ou autres caractères, car les moteurs de recherche considèrent les tirets comme des séparateurs de mots, mais pas nécessairement les underscores. Il est recommandé d’utiliser systématiquement des lettres minuscules pour éviter toute confusion, certains serveurs traitant les URL comme sensibles à la casse.
La structure des URL doit refléter l’organisation logique du contenu de votre site. Une structure hiérarchique comme exemple.com/produits/electronique/ordinateurs/portables-gaming indique clairement la relation entre les différentes sections et aide les utilisateurs à se situer sur le site. Cette structure facilite également l’indexation par les moteurs de recherche. Lors de la planification de la structure d’URL, pensez à l’évolution future de votre site et concevez des liens qui resteront pertinents et fonctionnels à mesure que le contenu s’enrichit.
Concepts avancés sur les URL : fragments, ancres et deep linking
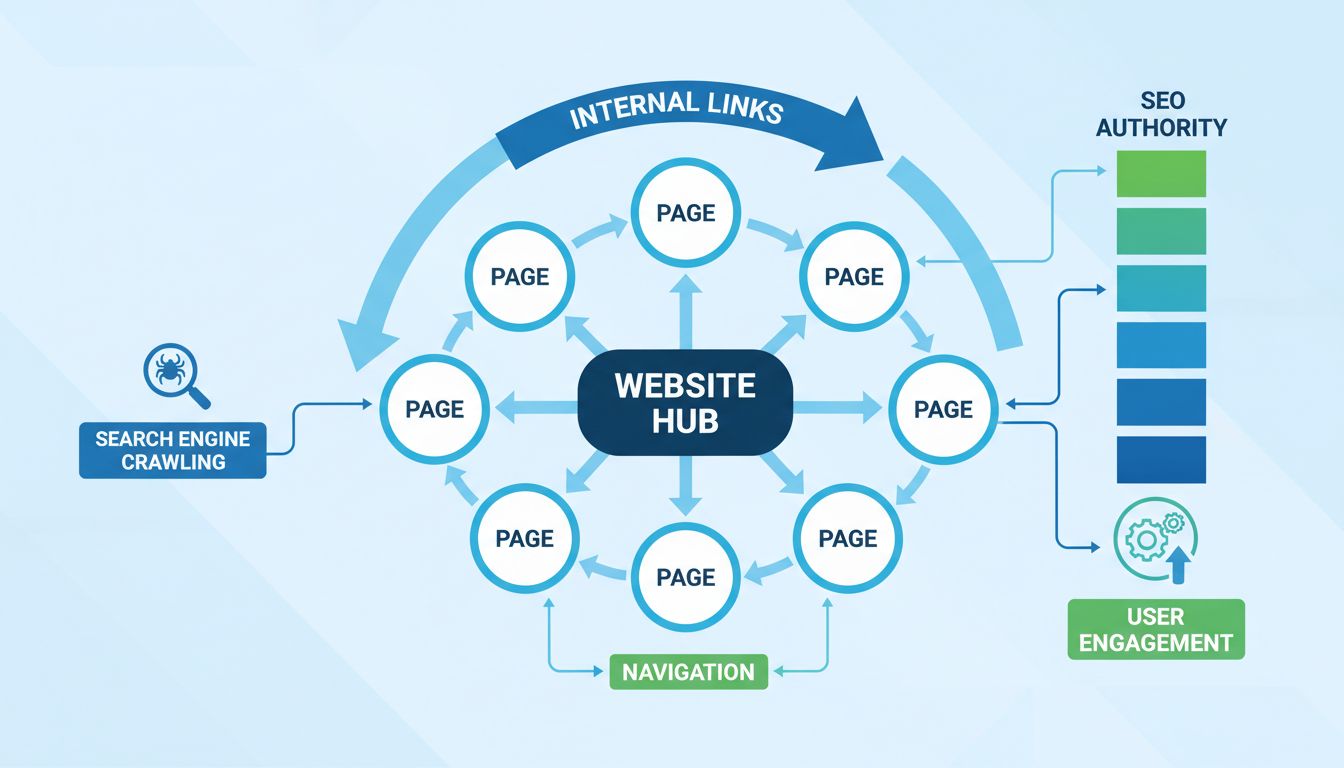
Les fragments d’URL, signalés par un symbole dièse (#) suivi d’un identifiant, permettent de lier directement à une section précise d’une page. Par exemple, exemple.com/article#section-2 amènera le navigateur à afficher la page et à faire défiler automatiquement jusqu’à la section portant l’ID « section-2 ». Les fragments sont entièrement traités par le navigateur côté client et ne sont pas envoyés au serveur, ce qui les rend utiles pour améliorer l’expérience utilisateur sans traitement côté serveur. De nombreux sites modernes utilisent abondamment les fragments pour créer des expériences fluides, notamment sur les applications monopages (SPA), où différentes sections de contenu sont accessibles sans rechargement complet.
Les liens d’ancrage, créés à l’aide des balises HTML avec des attributs d’ID, fonctionnent de pair avec les fragments pour permettre une navigation précise au sein d’une page. Lorsqu’un utilisateur clique sur un lien d’ancrage ou visite une URL avec fragment, le navigateur fait défiler automatiquement jusqu’à l’élément correspondant à l’ID. Cette fonctionnalité est particulièrement utile pour les contenus longs comme les articles, la documentation ou les guides, où l’on souhaite parfois accéder directement à une section précise. Les moteurs de recherche reconnaissent et indexent les liens d’ancrage, ce qui leur permet de proposer des liens directs vers des sections spécifiques dans les résultats, améliorant ainsi le taux de clics et la satisfaction des utilisateurs.
Le deep linking désigne la pratique consistant à lier directement à un contenu spécifique d’un site plutôt qu’à la page d’accueil. Les liens profonds sont essentiels pour l’expérience utilisateur et le SEO, car ils permettent d’accéder directement à ce que l’on recherche sans naviguer à travers plusieurs pages. Les moteurs de recherche favorisent les sites qui utilisent efficacement le deep linking, car cela témoigne d’une bonne organisation de l’information. Pour les affiliés et créateurs de contenu, le deep linking est particulièrement important car il permet de diriger les visiteurs vers des produits, articles ou ressources très spécifiques et pertinents pour leur audience.
Le rôle des liens de site web dans l’affiliation et le suivi
Pour les spécialistes du marketing d’affiliation, comprendre le fonctionnement des liens de site web est indispensable pour gérer efficacement les campagnes et analyser les performances. Les liens d’affiliation sont des URL spécialisées qui intègrent des paramètres de suivi identifiant l’affilié, la campagne et d’autres informations pertinentes. Lorsqu’un utilisateur clique sur un lien d’affiliation et effectue un achat ou une action souhaitée, les paramètres de suivi permettent au réseau d’attribuer la conversion au bon affilié et à la bonne campagne. Cette attribution est essentielle pour calculer les commissions et mesurer la performance des campagnes.
PostAffiliatePro, la plateforme de gestion d’affiliation de référence, offre des outils avancés pour créer, gérer et suivre les liens d’affiliation. La plateforme permet aux affiliés de générer des liens personnalisés avec des paramètres de suivi intégrés, de surveiller en temps réel les taux de clics et de conversions, et d’optimiser leurs campagnes grâce à des analyses détaillées de performance. Le système sophistiqué de gestion de liens de PostAffiliatePro garantit un suivi précis sur plusieurs canaux et appareils, fournissant aux affiliés les données nécessaires pour maximiser leurs gains. Les fonctionnalités de raccourcissement d’URL de la plateforme rendent les liens d’affiliation plus partageables sur les réseaux sociaux tout en maintenant toutes les capacités de suivi.
Comprendre la structure des URL et des paramètres est particulièrement important pour les affiliés utilisant PostAffiliatePro. La plateforme permet de personnaliser les paramètres de suivi afin de capturer des informations spécifiques sur les sources de trafic, les campagnes et le comportement des utilisateurs. En utilisant intelligemment les paramètres d’URL, les affiliés peuvent segmenter leur trafic et identifier quelles campagnes et quels canaux sont les plus rentables. Cette approche basée sur les données permet une optimisation continue des campagnes et conduit à de meilleurs résultats et à un retour sur investissement accru.
Optimisez vos liens d'affiliation avec PostAffiliatePro
Maîtrisez la gestion et le suivi des liens avec le logiciel d'affiliation leader du secteur. PostAffiliatePro offre un suivi avancé des URL, une gestion des liens et des analyses complètes pour maximiser la performance de votre marketing d'affiliation.
Pourquoi les liens sont-ils importants sur un site web ? Guide SEO complet
Découvrez pourquoi les liens sont essentiels à la réussite d'un site web. Apprenez comment les liens internes et externes améliorent le SEO, l'expérience utilis...
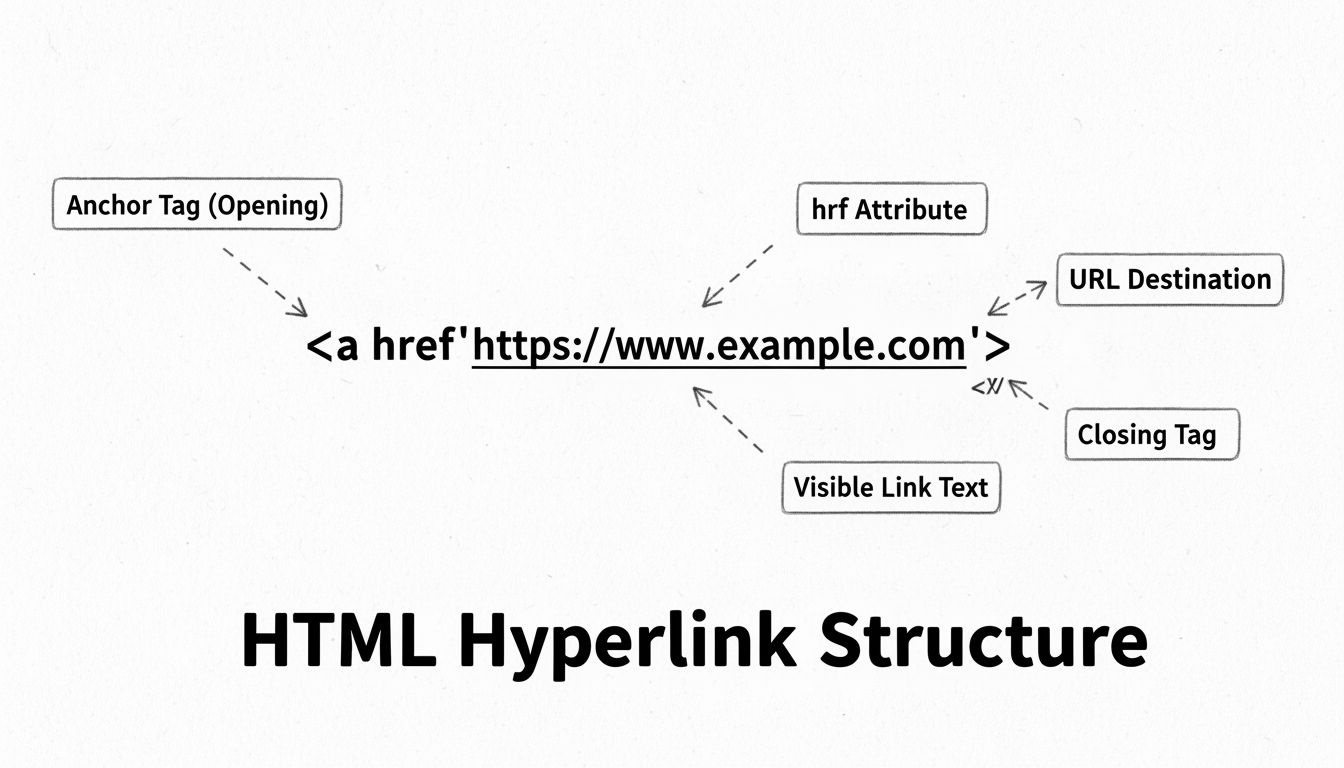
Comment puis-je créer un hyperlien ? Guide HTML complet
Apprenez à créer des hyperliens en HTML avec la balise <a>. Maîtrisez les attributs href, les URL absolues et relatives, les bonnes pratiques de liens et les te...
Qu'est-ce qu'une URL ? Définition simple et compréhensible
Un localisateur uniforme de ressource (URL) définit l'adresse d'une page web. Il se compose de trois parties : le protocole, le nom d'hôte et le nom de fichier....
5 min de lecture
URL
AffiliateMarketing
+3
Vous serez entre de bonnes mains !
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.