Pourquoi les robots d’indexation web sont-ils appelés araignées ? Comprendre la technologie d’indexation du web
Découvrez pourquoi les robots d’indexation web sont appelés araignées, comment ils fonctionnent et leur rôle essentiel dans l’indexation des moteurs de recherche. Plongez dans les mécanismes techniques du crawling web en 2025.
Pourquoi les robots d’indexation web sont-ils appelés araignées ?
Les robots d’indexation web sont appelés araignées car ils parcourent systématiquement le web en suivant les liens d’une page à l’autre, à l’image d’une araignée se déplaçant dans sa toile. Le terme « araignée » est une métaphore appropriée pour ces bots automatisés qui explorent le réseau interconnecté des sites web afin de découvrir, indexer et organiser le contenu pour les moteurs de recherche.
Comprendre la métaphore de l’araignée
Le terme « araignée » pour désigner les robots d’indexation web provient d’une comparaison métaphorique entre la manière dont ces bots automatisés naviguent sur Internet et celle dont les araignées évoluent dans leur toile. De la même façon qu’une araignée tisse une toile complexe pour capturer et organiser les informations de son environnement, les robots d’indexation explorent le réseau interconnecté d’hyperliens du World Wide Web pour découvrir, analyser et organiser le contenu numérique. La métaphore est particulièrement pertinente car les deux entités opèrent de manière systématique à travers des réseaux complexes, suivant des chemins pour atteindre de nouvelles destinations et collecter des informations. Cette convention de nommage s’est tellement ancrée dans la technologie que les termes « araignée », « robot d’indexation » et « bot » sont désormais utilisés de façon interchangeable pour parler de la technologie d’indexation web. La similarité visuelle et conceptuelle entre la toile d’une araignée et la structure d’Internet rend cette terminologie intuitive et mémorable aussi bien pour les professionnels techniques que pour les utilisateurs généraux.
Comment les araignées web naviguent sur Internet
Les araignées web fonctionnent selon un processus sophistiqué mais systématique, démarrant à partir d’un point d’entrée appelé « URL de départ » (seed URL). Depuis cet emplacement initial, l’araignée analyse le code HTML de la page web et extrait tous les hyperliens présents. Elle suit ensuite ces liens vers de nouvelles pages, répétant continuellement le processus pour étendre sa portée sur le web. Cette approche méthodique permet aux araignées de découvrir des millions de pages interconnectées sans intervention humaine. L’araignée gère ce qu’on appelle une « frontière de crawl » (crawl frontier), c’est-à-dire une file d’attente d’URLs déjà découvertes mais pas encore visitées. Selon des politiques et des algorithmes spécifiques de crawling, l’araignée priorise les URLs à visiter ensuite, en tenant compte de facteurs comme l’importance de la page, la fréquence de mise à jour et la pertinence par rapport aux objectifs d’indexation du moteur de recherche.
Lancez votre programme d'affiliation aujourd'hui
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
L’architecture technique des robots d’indexation web
Les araignées web modernes reposent sur une architecture technique sophistiquée leur permettant de traiter efficacement d’énormes volumes de données. Les composants principaux d’un robot d’indexation incluent le système de gestion du « frontier d’URL », qui organise et priorise les URLs à explorer ; le mécanisme de récupération, qui télécharge rapidement le contenu des pages ; le moteur d’analyse, qui extrait les liens et métadonnées du HTML ; et le système d’indexation, qui stocke les informations traitées pour la recherche. Les araignées web doivent aussi appliquer des politiques de courtoisie pour ne pas surcharger les serveurs cibles, des politiques de revisite pour déterminer la fréquence de re-crawl des pages, et des politiques de sélection pour décider quels liens sont les plus intéressants à suivre. Les araignées contemporaines sont capables de gérer le contenu JavaScript et AJAX, même si elles privilégient encore le HTML classique pour une découverte fiable des contenus. La nature distribuée du crawling moderne permet aux grandes araignées d’opérer sur plusieurs serveurs simultanément, ce qui leur permet d’explorer différents sites en parallèle et d’accroître considérablement leur efficacité et leur couverture.
Différences entre araignées, robots d’indexation et scrapers
Bien que les termes « araignée » et « robot d’indexation » soient souvent utilisés de façon interchangeable, il est important de comprendre qu’ils désignent la même technologie sous des appellations différentes. En revanche, les araignées se distinguent nettement des scrapers web, souvent confondus avec les robots d’indexation. La différence principale réside dans leur objectif et leur portée : les robots d’indexation se concentrent sur la collecte générale d’informations sur les sites web et leur structure, suivant largement les liens pour constituer des index exhaustifs. Les araignées, lorsqu’elles sont utilisées spécifiquement par les moteurs de recherche, se focalisent sur l’indexation du contenu textuel afin de le rendre accessible et consultable. Les scrapers, quant à eux, sont des outils ciblés conçus pour extraire des éléments de données spécifiques (prix, coordonnées, avis…) de certains sites. Les scrapers visent généralement des sites ou des types de données particuliers, plutôt que d’explorer l’ensemble du web. De plus, les robots d’indexation et les araignées respectent généralement les fichiers robots.txt et les conditions d’utilisation des sites, alors que les scrapers peuvent s’en affranchir. Comprendre ces distinctions est essentiel pour les propriétaires de sites web et les développeurs qui souhaitent contrôler l’accès et l’indexation de leur contenu par des systèmes automatisés.
Le rôle des araignées web dans le fonctionnement des moteurs de recherche
Les araignées web jouent un rôle absolument fondamental dans le fonctionnement des moteurs de recherche et la valeur qu’ils offrent aux utilisateurs du monde entier. Sans une exploration et une indexation continues par les araignées, les moteurs n’auraient aucun moyen de savoir quels sites existent, quel contenu ils proposent, ou quelle est la pertinence de ce contenu pour les requêtes des utilisateurs. Lorsqu’une araignée parcourt une page web, elle évalue de nombreux facteurs, notamment la structure, la pertinence du contenu, l’utilisation des mots-clés et les signaux d’expérience utilisateur. Ces informations sont ensuite stockées dans d’immenses index que les moteurs utilisent pour relier les requêtes aux résultats les plus pertinents. La qualité et la fréquence du crawling influent directement sur la rapidité d’apparition des nouveaux contenus dans les résultats de recherche et sur l’exactitude du classement des pages. Des moteurs tels que Google, Bing, Baidu ou Yahoo disposent chacun de leurs propres bots propriétaires — Googlebot, Bingbot, Baiduspider et Slurp respectivement — avec des algorithmes et stratégies de crawling optimisés pour leurs objectifs et utilisateurs spécifiques.
Comparaison des principales technologies d’araignées web
Bot araignée
Moteur de recherche
Fonction principale
Stratégie de crawl
Caractéristiques clés
Googlebot
Google
Indexer les pages pour Google Search
Crawling distribué avec variantes mobile et desktop
Gère JavaScript, privilégie l’indexation mobile-first, respecte le budget de crawl
Bingbot
Microsoft Bing
Indexer les pages pour Bing Search
Crawling en parallèle sur plusieurs serveurs
Utilisation efficace de la bande passante, respecte robots.txt, prend en charge plusieurs types de contenus
Baiduspider
Baidu
Indexer les pages pour Baidu Search
Optimisé pour le contenu en langue chinoise
Spécialisé pour le web asiatique, gère le chinois simplifié et traditionnel
DuckDuckBot
DuckDuckGo
Indexer les pages pour une recherche axée sur la confidentialité
Crawling respectueux axé sur la vie privée
Collecte minimale de données, respecte les préférences de confidentialité des utilisateurs
YandexBot
Yandex
Indexer les pages pour Yandex Search
Crawling distribué avec optimisation régionale
Optimisé pour les contenus russes et d’Europe de l’Est
Comment les propriétaires de sites peuvent optimiser le crawling des araignées
Les propriétaires de sites disposent de nombreux outils et stratégies pour optimiser la façon dont les araignées explorent et indexent leur contenu. Créer un fichier sitemap.xml complet offre aux araignées une feuille de route claire de toutes les pages à indexer, ce qui améliore l’efficacité du crawling et évite d’omettre des pages importantes. L’optimisation des balises meta, y compris les titres et descriptions, aide les araignées à comprendre le contenu des pages et améliore leur apparence dans les résultats de recherche. Mettre en place un fichier robots.txt bien structuré permet d’orienter les araignées vers le contenu important et d’écarter les pages à ne pas indexer, comme les panneaux d’administration ou les contenus dupliqués. Mettre à jour et ajouter régulièrement du contenu frais encourage les araignées à revisiter le site plus fréquemment, maintenant ainsi l’index à jour et améliorant la visibilité dans les moteurs. Les propriétaires doivent également veiller à une architecture de site propre et logique, avec une navigation hiérarchique claire facilitant la découverte de toutes les pages par les araignées. Améliorer la vitesse de chargement des pages est essentiel car les araignées disposent d’un « budget de crawl » limité — c’est-à-dire la quantité de ressources allouées par les moteurs à l’exploration d’un site — et des pages rapides leur permettent d’indexer plus de contenu dans ce budget.
Défis et limites du crawling web
Malgré leur sophistication, les araignées web se heurtent à de nombreux défis techniques pouvant limiter leur efficacité. Le contenu dynamique généré par JavaScript constitue un obstacle majeur, car toutes les araignées ne peuvent pas exécuter ce code pour afficher les pages comme les utilisateurs. Les limitations de taux imposées par les sites restreignent le nombre de requêtes qu’une araignée peut effectuer dans un laps de temps donné, ce qui peut empêcher l’indexation complète de grands sites. Les CAPTCHAs et autres mesures anti-bots peuvent bloquer l’accès des araignées, même si les bots légitimes des moteurs de recherche sont généralement autorisés. Le contenu dupliqué sur plusieurs URLs embrouille les araignées sur la version à indexer et classer, ce qui peut nuire à la visibilité. Les « pièges à robots » — boucles infinies involontaires ou intentionnelles dans la structure du site — gaspillent les ressources des araignées et leur budget de crawl sans apporter d’indexation productive. De plus, la croissance exponentielle du contenu web fait qu’il est impossible pour les araignées d’explorer et d’indexer tout le web, d’où la nécessité d’algorithmes sophistiqués pour prioriser le contenu le plus pertinent. Enfin, les pages protégées par mot de passe ou nécessitant une authentification restent généralement inaccessibles aux araignées publiques, ce qui limite l’indexation du contenu privé ou réservé aux membres.
L’évolution de la technologie des araignées web en 2025
La technologie des araignées web continue d’évoluer rapidement à mesure que l’Internet s’étend et se complexifie. Les araignées modernes sont de plus en plus capables de gérer des technologies avancées telles que les applications monopages, les progressive web apps et le rendu dynamique des contenus. L’intelligence artificielle et l’apprentissage automatique sont intégrés aux algorithmes des araignées pour mieux saisir le contexte, l’intention utilisateur et la qualité des pages. L’essor de l’IA générative impose de nouveaux besoins au crawling, les systèmes d’IA ayant besoin d’informations constamment actualisées, pertinentes et fiables. Les robots d’indexation d’entreprise sont devenus plus sophistiqués, permettant aux entreprises d’explorer leurs propres sites pour la recherche interne, la gestion de contenu ou le suivi des performances. L’accent sur l’efficacité du crawl s’est intensifié avec la croissance et la complexification des sites, les araignées adoptant désormais des algorithmes de priorisation plus intelligents pour maximiser la valeur de chaque requête. Les enjeux de confidentialité influent également sur le développement des araignées, avec une attention croissante portée au respect de la vie privée des utilisateurs tout en assurant une découverte et une indexation efficace des contenus. À l’avenir, les araignées web seront encore plus intelligentes et efficaces, exploitant des technologies avancées pour naviguer dans un paysage numérique de plus en plus complexe, tout en respectant les politiques des sites et la vie privée des utilisateurs.
Optimisez votre réseau d’affiliation avec PostAffiliatePro
Tout comme les araignées web explorent et indexent systématiquement l’ensemble du web, PostAffiliatePro suit et optimise systématiquement chaque relation d’affiliation dans votre réseau. Notre technologie de suivi avancée garantit qu’aucune commission n’est oubliée et qu’aucune opportunité n’est manquée.
Spiders SEO : Pourquoi sont-ils importants pour votre site
Les spiders sont des robots créés pour le spamming, pouvant causer de nombreux problèmes à votre entreprise. Découvrez-en plus à leur sujet dans cet article....
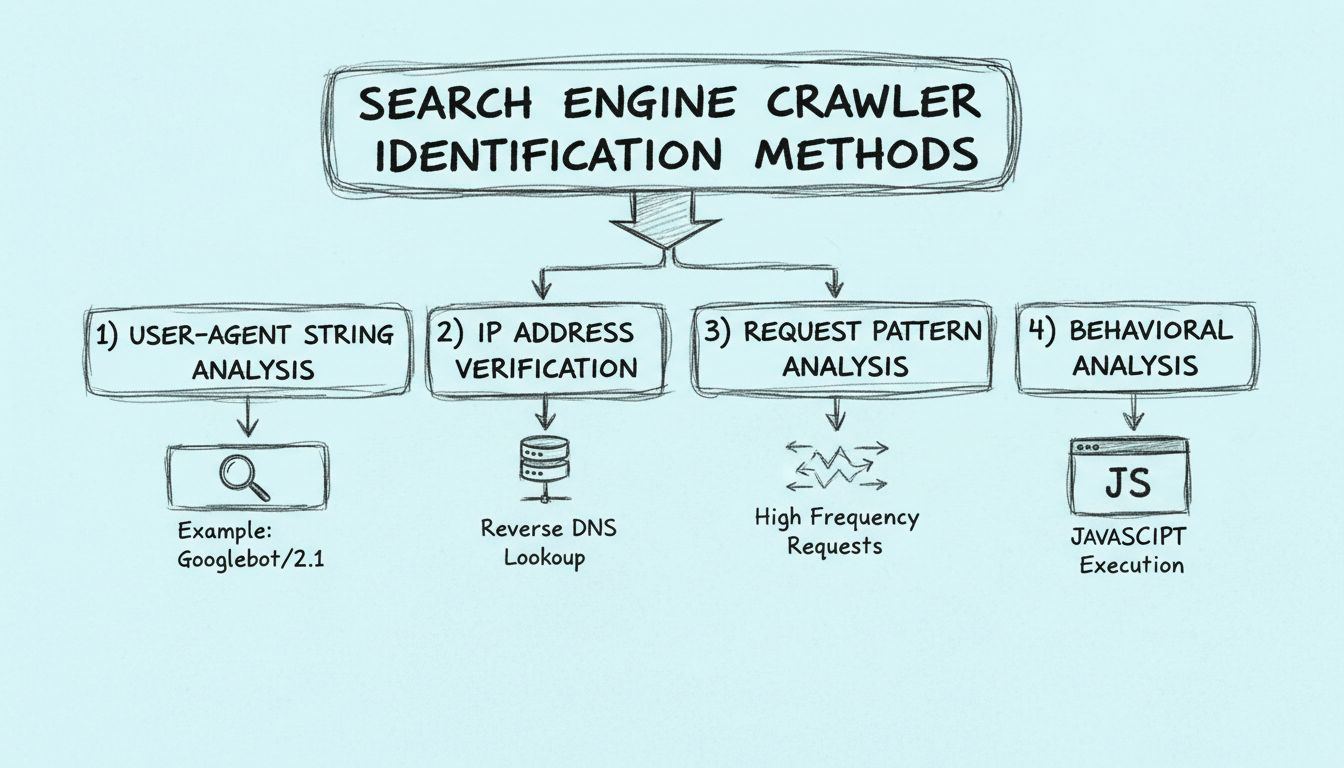
Comment identifier les robots d’indexation des moteurs de recherche ?
Découvrez comment identifier les robots d’indexation des moteurs de recherche grâce aux chaînes user-agent, aux adresses IP, aux schémas de requêtes et à l’anal...
Les crawlers et leur rôle dans le classement des moteurs de recherche
Les crawlers accumulent des données et des informations sur Internet en visitant des sites web et en lisant leurs pages. Découvrez-en plus à leur sujet.
6 min de lecture
SEO
Crawlers
+4
Vous serez entre de bonnes mains !
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.