Le contenu dupliqué est-il mauvais pour le SEO ? Guide complet sur l'impact du contenu dupliqué
Découvrez pourquoi le contenu dupliqué nuit au SEO, comment il affecte le classement, et les solutions éprouvées comme les balises canoniques et les redirections 301 pour corriger les problèmes de contenu dupliqué en 2025.
Le contenu dupliqué est-il mauvais pour le SEO ?
Oui, le contenu dupliqué peut avoir un impact négatif sur le SEO en embrouillant les moteurs de recherche sur la version à classer, en diluant la valeur des liens entre plusieurs URLs, en gaspillant le budget de crawl, et en permettant potentiellement à du contenu copié de surpasser vos pages originales. Bien que Google n'applique pas de pénalité spécifique pour contenu dupliqué, les effets indirects peuvent nuire considérablement à votre visibilité dans les moteurs de recherche et à votre trafic organique.
Comprendre le contenu dupliqué et son impact sur le SEO
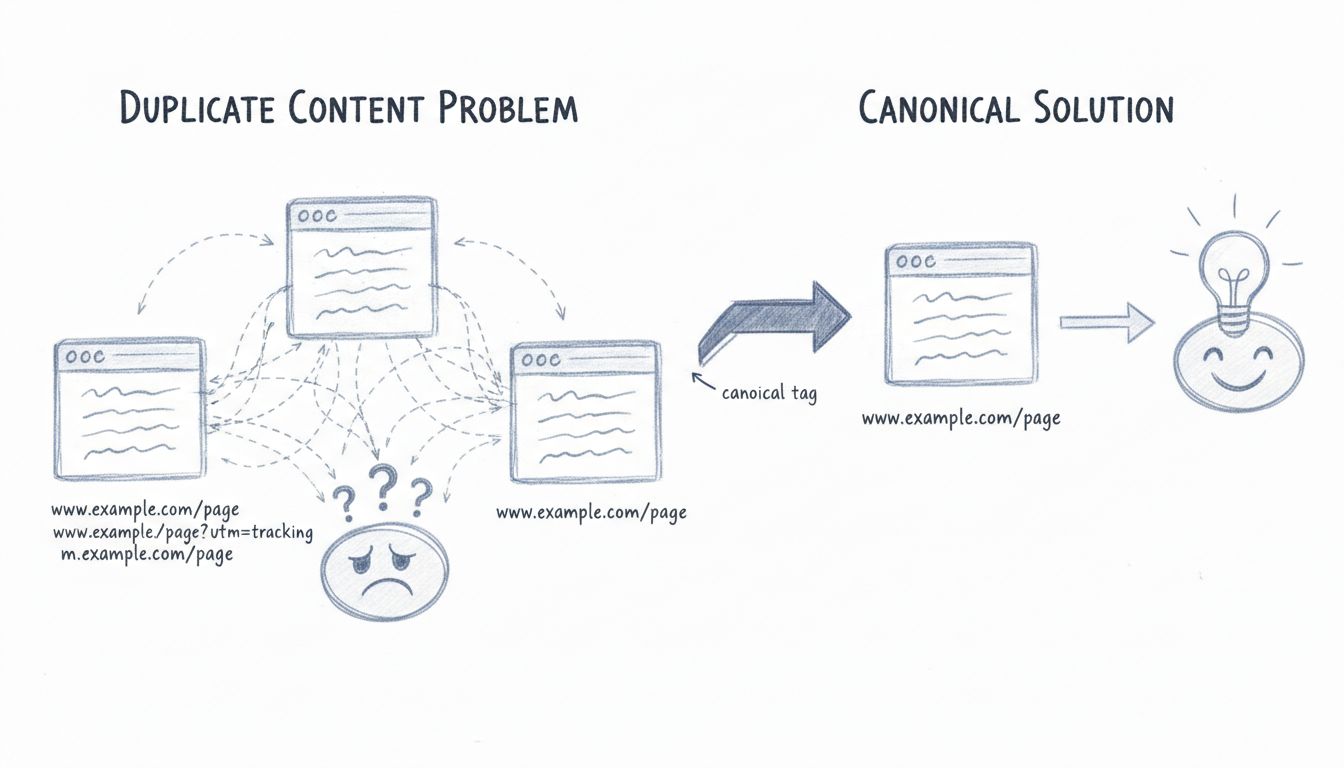
Le contenu dupliqué désigne un contenu identique ou substantiellement similaire qui apparaît sur Internet à plusieurs URLs. Cela peut se produire au sein d’un même site ou sur différents domaines. Selon des données récentes, environ 25 à 30 % du web est composé de contenu dupliqué, ce qui en fait l’un des défis techniques SEO les plus courants pour les propriétaires de sites aujourd’hui. Lorsque les moteurs de recherche rencontrent plusieurs versions d’un même contenu, ils doivent décider quelle version est la source faisant autorité, laquelle indexer, et laquelle classer dans les résultats de recherche. Ce processus de décision crée plusieurs complications qui peuvent impacter négativement la visibilité et la performance de votre site dans les résultats organiques.
La confusion créée par le contenu dupliqué pour les moteurs de recherche est fondamentalement différente d’une pénalité pure et simple. Google a clairement indiqué à plusieurs reprises qu’il n’existe pas de pénalité spécifique pour contenu dupliqué. Cependant, cela ne signifie pas que le contenu dupliqué est inoffensif. Les effets indirects du contenu dupliqué peuvent être tout aussi nuisibles à vos performances SEO qu’une sanction directe. Comprendre ces effets est essentiel pour maintenir un site sain, bien optimisé et performant dans les résultats de recherche.
Comment le contenu dupliqué embrouille les moteurs de recherche
Les moteurs de recherche comme Google utilisent des algorithmes sophistiqués pour déterminer quelle version du contenu dupliqué doit être indexée et classée. Lorsque plusieurs versions d’un même contenu existent, les moteurs de recherche doivent regrouper ces pages dans ce qu’on appelle un “cluster de doublons”. À partir de ce cluster, Google sélectionne l’URL qu’il estime être la meilleure pour représenter le contenu dans les résultats de recherche. Ce processus, appelé canonicalisation, est censé consolider la valeur des liens et la puissance de classement sur une seule URL.
Cependant, ce processus automatique n’est pas toujours parfait. Les moteurs de recherche peuvent sélectionner la mauvaise version comme URL canonique, ce qui conduit à l’apparition de liens indésirables ou peu conviviaux dans les résultats. Par exemple, si votre site propose le même contenu sur example.com/page/ et example.com/page?utm_source=newsletter, Google pourrait choisir de classer la version avec des paramètres de suivi au lieu de la version propre et plus conviviale. Lorsque les utilisateurs voient ces URLs peu attrayantes dans les résultats, ils sont moins enclins à cliquer dessus, ce qui se traduit par un taux de clics plus faible et une diminution du trafic organique, même si votre page est bien classée.
Lancez votre programme d'affiliation aujourd'hui
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
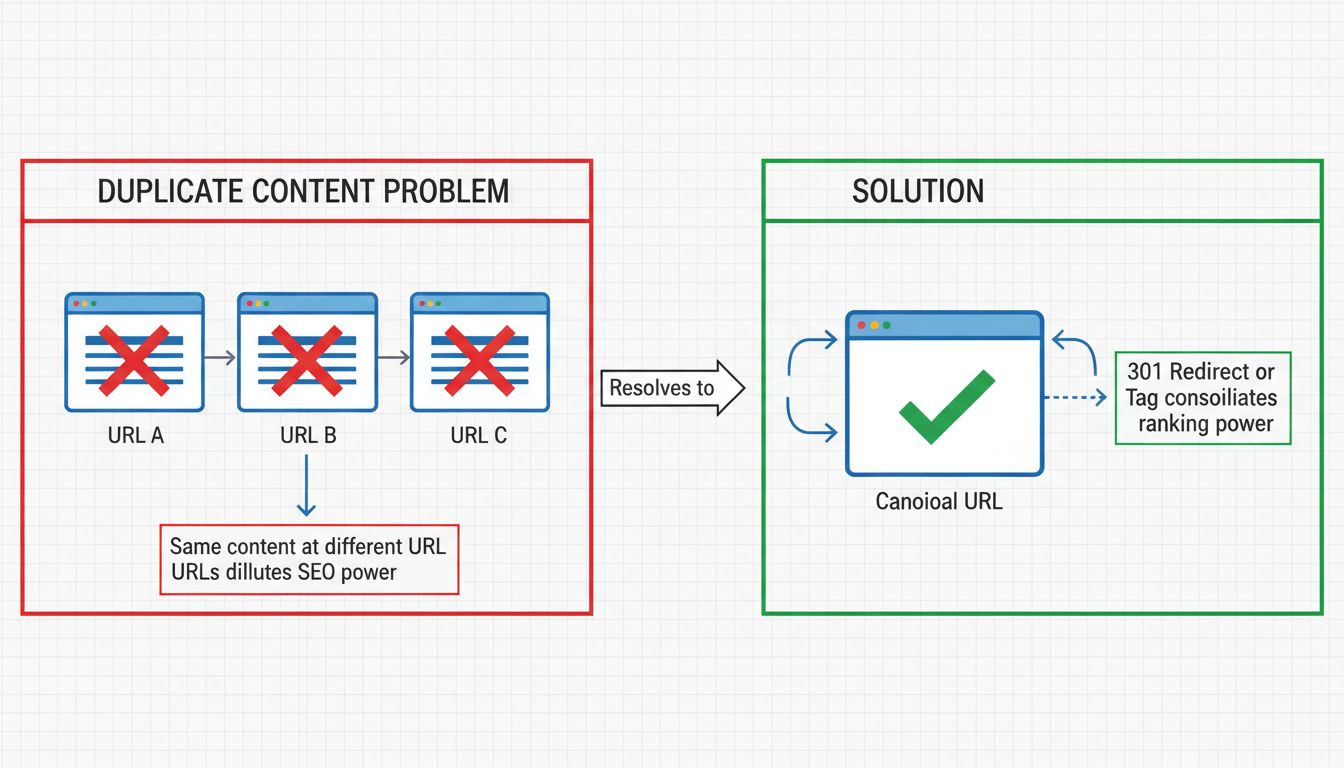
L’une des façons les plus significatives dont le contenu dupliqué nuit au SEO est la dilution de la valeur des liens. Lorsque le même contenu existe à plusieurs URLs, les backlinks d’autres sites peuvent pointer vers différentes versions de ce contenu. Au lieu que toute la valeur des liens se concentre sur une seule page faisant autorité, elle se disperse entre plusieurs URLs dupliquées. Cette fragmentation affaiblit le signal d’autorité global utilisé par les moteurs de recherche pour le classement.
Prenons un exemple concret : si votre contenu est accessible à la fois sur buffer.com/library/social-media-manager-checklist et buffer.com/resources/social-media-manager-checklist, des sites externes peuvent faire un lien vers l’une ou l’autre version. Une URL peut accumuler 106 domaines référents tandis que l’autre en a 144. Bien que le processus de canonicalisation de Google soit censé consolider ces liens vers une seule URL, dans la pratique, les deux URLs peuvent continuer à être classées séparément, ce qui signifie que la valeur des liens n’est pas entièrement consolidée. Cela aboutit à deux pages modérément fortes au lieu d’une page très autoritaire qui pourrait se classer plus haut et capter davantage de trafic.
Gaspillage du budget de crawl et délais d’indexation
Les moteurs de recherche allouent un budget de crawl limité à chaque site, c’est-à-dire le nombre de pages qu’ils vont explorer et indexer sur une période donnée. Si votre site contient beaucoup de contenu dupliqué, les moteurs de recherche gaspillent ce précieux budget en explorant à plusieurs reprises des pages dupliquées au lieu de découvrir et d’indexer du contenu nouveau ou actualisé. Cela est particulièrement problématique pour les sites ayant des temps de réponse serveur plus lents ou une bande passante limitée, car la limite de crawl de Google est plus élevée pour les sites plus réactifs.
Lorsque le budget de crawl est gaspillé sur des doublons, cela peut entraîner des délais dans l’indexation de nouvelles pages ou la réindexation de pages mises à jour. Cela signifie que le contenu frais que vous publiez peut mettre plus de temps à apparaître dans les résultats, et que les modifications apportées à du contenu existant peuvent ne pas être reflétées aussi rapidement que nécessaire dans l’index de Google. Pour les sites riches en contenu ou ceux qui publient fréquemment, ce retard peut entraîner une perte significative de trafic et de visibilité organique.
Les paramètres de suivi (codes UTM), identifiants de session et filtres créent plusieurs URLs avec le même contenu
Utiliser les balises canoniques ou des redirections 301 pour consolider vers des URLs propres
HTTPS vs HTTP
Contenu accessible en version sécurisée et non sécurisée
Configurer le serveur pour rediriger tout le trafic vers la version HTTPS
WWW vs Non-WWW
Contenu accessible à la fois sur www.example.com
et example.com
Définir le domaine préféré dans Google Search Console et utiliser des redirections
Barre oblique finale
URLs avec et sans barre oblique considérées comme différentes pages
Mettre en place des redirections cohérentes (par exemple, toujours utiliser la barre oblique)
Versions mobiles
URLs mobiles séparées (m.example.com) avec le même contenu
Utiliser des balises rel=“alternate” ou le responsive design
Pages AMP
Les pages AMP créent des versions dupliquées
Rendre les pages AMP canoniques vers les versions non-AMP
URLs pour impression
Versions imprimables avec le même contenu
Rendre les versions imprimables canoniques vers la page d’origine
Pages de tags/catégories
Plusieurs pages de tags avec le même contenu lorsqu’un seul article utilise ces tags
Passer en noindex les pages de tags peu utiles ou fusionner les tags
Pagination
Pagination des commentaires ou des produits créant de nombreuses pages similaires
Utiliser rel=“prev” et rel=“next” ou passer en noindex les pages paginées
Environnements de préproduction
Sites de développement/préproduction indexés par les moteurs
Protéger la préproduction avec robots.txt, noindex ou une authentification
Empêcher que du contenu copié ne vous surpasse
Si les problèmes de contenu dupliqué internes à votre site sont courants, le contenu dupliqué externe peut aussi nuire à votre SEO. Lorsque d’autres sites copient ou republient votre contenu sans autorisation, ils créent du contenu dupliqué sur plusieurs domaines. Dans de rares cas, si le site copieur a une autorité de domaine supérieure à la vôtre, Google peut à tort considérer sa version comme originale et la classer devant la vôtre. C’est particulièrement problématique pour les nouveaux sites ou ceux ayant moins d’autorité.
Pour vous en prémunir, mettez en place des balises canoniques auto-référencées sur toutes vos pages. Une balise canonique auto-référencée pointe vers la page sur laquelle elle se trouve, signalant ainsi aux moteurs de recherche que c’est la version faisant autorité. Même si tous les copieurs ne conservent pas votre code HTML, ceux qui le font verront votre balise canonique et comprendront que votre version est l’originale. De plus, si vous syndiquez volontairement votre contenu sur d’autres sites, demandez-leur toujours d’inclure un lien canonique vers votre page d’origine. Ainsi, même si votre contenu apparaît sur plusieurs sites, tout le crédit SEO revient au vôtre.
Solutions techniques pour corriger le contenu dupliqué
Implémenter les balises canoniques
La balise canonique est l’une des solutions les plus efficaces et largement utilisées pour gérer le contenu dupliqué. Cet élément HTML indique aux moteurs de recherche quelle version d’une page doit être considérée comme la source faisant autorité. La balise canonique se place dans la section <head> de votre HTML et ressemble à ceci :
Lorsque vous ajoutez cette balise aux pages dupliquées en pointant vers la version canonique (originale), les moteurs de recherche consolident la puissance de classement et la valeur des liens sur cette seule URL. La balise canonique transmet à peu près autant de valeur de lien qu’une redirection 301, mais elle est souvent plus facile à mettre en place car elle ne nécessite pas de configuration côté serveur. Cela la rend particulièrement utile pour gérer les doublons créés par les paramètres d’URL, les versions mobiles ou les pages AMP.
Utiliser les redirections 301
Une redirection 301 est une redirection permanente qui indique aux utilisateurs et aux moteurs de recherche qu’une page a été déplacée de façon définitive vers un nouvel emplacement. En mettant en place des redirections 301 des URLs dupliquées vers la version canonique, vous consolidez toute la puissance de classement et la valeur des liens sur l’URL cible. C’est souvent la meilleure solution lorsque vous souhaitez éliminer complètement les URLs dupliquées de votre site.
Par exemple, si votre site est accessible à la fois sur http://example.com et https://www.example.com, vous devez configurer des redirections 301 pour que tout le trafic et les crawlers soient dirigés vers la version préférée. Ainsi, les moteurs de recherche n’indexent qu’une seule version de votre site, ce qui prévient les problèmes de contenu dupliqué. La redirection 301 transmet quasiment 100 % de la valeur des liens à la page de destination, ce qui en fait un excellent choix pour consolider le contenu dupliqué.
Balise Meta Robots Noindex
La balise meta robots noindex est particulièrement utile pour gérer le contenu dupliqué que vous souhaitez laisser accessible aux utilisateurs mais ne pas indexer par les moteurs. En ajoutant <meta name="robots" content="noindex,follow"> dans la section <head> d’une page, vous indiquez aux moteurs de ne pas inclure cette page dans leur index tout en leur permettant de suivre les liens présents sur la page.
Cette solution est idéale pour gérer les doublons liés à la pagination, aux pages de tags, aux pages de filtres et à d’autres pages générées automatiquement qui n’apportent pas de valeur unique. Attention cependant : Google continue de crawler ces pages pour vérifier la directive noindex, donc il ne faut pas les bloquer dans le fichier robots.txt. La balise noindex est moins efficace que les balises canoniques ou les redirections 301 pour la consolidation de la valeur des liens, mais elle est excellente pour empêcher les pages dupliquées peu utiles d’encombrer les résultats de recherche.
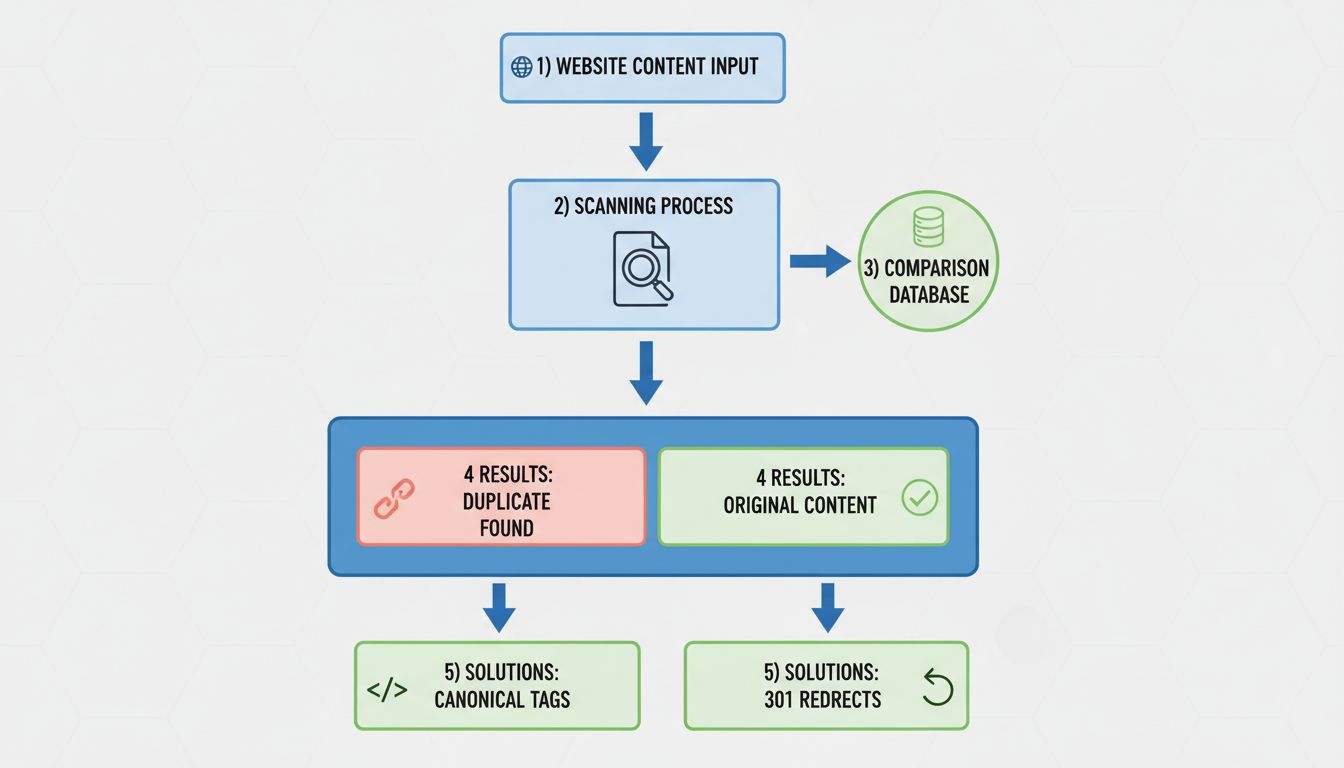
Détecter le contenu dupliqué sur votre site
Pour identifier les problèmes de contenu dupliqué sur votre site, effectuez régulièrement des audits complets à l’aide d’outils SEO spécialisés. Ces outils explorent l’ensemble de votre site et repèrent les pages ayant un contenu identique ou très similaire. Lors de l’analyse des résultats, recherchez les groupes de pages dupliquées sans balise canonique appropriée — ils sont mis en avant comme des problèmes à corriger.
Google Search Console fournit également des informations précieuses sur le contenu dupliqué. Le rapport de couverture indique les pages indexées par Google et signale des problèmes comme “Dupliqué, sans utilisateur ayant sélectionné de canonique” ou “Dupliqué, Google a choisi une canonique différente de l’utilisateur”. Ces avertissements signifient que Google a détecté un doublon sur votre site et ne le gère peut-être pas comme vous le souhaitez. L’outil d’inspection d’URL dans la Search Console vous permet aussi de vérifier comment Google traite des URLs spécifiques, en affichant si une page est indexée, canonisée ou bloquée à l’indexation.
Bonnes pratiques pour prévenir le contenu dupliqué
Prévenir le contenu dupliqué est bien plus facile que de le corriger par la suite. Commencez par établir des standards clairs d’URL pour votre site et maintenez cette cohérence dans toute votre architecture. Lors de la création de liens internes, liez toujours vers la même version des URLs — n’alternez pas entre les versions www et non-www, et ne variez pas la présence de la barre oblique finale. Cette cohérence aide les moteurs à comprendre votre structure d’URL préférée.
Pour les sites e-commerce utilisant une navigation à facettes avec filtres et options de tri, implémentez une gestion correcte des paramètres pour éviter la création de centaines de pages dupliquées. Utilisez les balises canoniques pour ramener les vues filtrées vers la page produit de base, ou l’outil de gestion des paramètres dans Google Search Console pour indiquer à Google quels paramètres doivent être ignorés lors du crawl.
Si vous utilisez un CMS comme WordPress, désactivez les fonctionnalités qui créent automatiquement du contenu dupliqué, telles que les pages dédiées aux pièces jointes d’images et les commentaires paginés. La plupart des CMS modernes proposent des réglages pour contrôler ces comportements. De plus, protégez vos environnements de préproduction et de développement de l’indexation à l’aide de directives robots.txt, de balises meta noindex ou d’une authentification HTTP pour empêcher les moteurs de crawler ces versions dupliquées de votre site.
L’essentiel sur le contenu dupliqué et le SEO
Même si Google ne sanctionne pas spécifiquement le contenu dupliqué, ses effets indirects peuvent nuire fortement aux performances SEO de votre site. Le contenu dupliqué perturbe les moteurs de recherche dans le choix de la version à classer, dilue la valeur des liens entre plusieurs URLs, gaspille votre budget de crawl, et peut permettre à des copies de surpasser vos pages originales. En mettant en œuvre des balises canoniques, des redirections 301 et une structure d’URL adaptée, vous pouvez prévenir et corriger les problèmes de contenu dupliqué avant qu’ils n’affectent votre visibilité.
La clé pour maintenir un site sain est d’être proactif dans la gestion du contenu dupliqué. Auditez régulièrement votre site, appliquez des stratégies de canonicalisation appropriées et maintenez une cohérence dans vos URLs. En prenant ces mesures, vous facilitez l’identification de votre contenu autoritaire par les moteurs, la consolidation de la valeur des liens sur vos URLs préférées, et l’exploration et l’indexation efficaces de votre site. Résultat : un meilleur classement, plus de trafic organique et de meilleures performances SEO globales pour votre site.
Optimisez votre site d'affiliation avec PostAffiliatePro
Gérez plusieurs programmes d'affiliation et évitez les problèmes de contenu dupliqué grâce aux fonctionnalités avancées de suivi et de gestion de contenu de PostAffiliatePro. Assurez-vous que vos efforts de marketing d'affiliation génèrent une valeur SEO maximale.
Comment résoudre les problèmes de contenu dupliqué : Guide SEO complet
Découvrez des méthodes éprouvées pour résoudre les problèmes de contenu dupliqué, y compris les redirections 301, les balises canoniques et les directives noind...
Découvrez comment vérifier la présence de contenu dupliqué à l’aide d’outils comme Copyscape, Siteliner et Google Search Console. Découvrez les méthodes manuell...
Le contenu dupliqué désigne un contenu identique ou similaire apparaissant sur plusieurs URL, soit au sein d’un même site web, soit sur différents sites. Bien q...
6 min de lecture
SEO
Content
+3
Vous serez entre de bonnes mains !
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.