Comment fonctionnent les crawlers web ? Guide technique complet
Découvrez comment fonctionnent les crawlers web, des URLs sources à l’indexation. Comprenez le processus technique, les types de crawlers, les règles robots.txt et l’impact des crawlers sur le SEO et le marketing d’affiliation.
Comment fonctionnent les crawlers web ?
Les crawlers web fonctionnent en envoyant des requêtes HTTP à des sites web à partir d’URLs sources, en suivant les hyperliens pour découvrir de nouvelles pages, en analysant le contenu HTML pour extraire des informations, en respectant les règles du fichier robots.txt et en stockant les données collectées dans des index consultables. Ils visitent systématiquement les pages, extraient des métadonnées et des liens, puis répètent le processus pour maintenir à jour les bases de données des moteurs de recherche.
Comprendre les fondamentaux des crawlers web
Les crawlers web, également appelés spiders ou bots, sont des programmes automatisés qui parcourent systématiquement Internet pour découvrir, télécharger et analyser le contenu des sites web. Ces agents intelligents constituent l’épine dorsale de l’infrastructure des moteurs de recherche, permettant à des plateformes comme Google, Bing et d’autres services de recherche de construire des index complets de milliards de pages web. L’objectif principal des crawlers web est de collecter et d’organiser les informations des sites afin que les moteurs de recherche puissent rapidement fournir des résultats pertinents lors des recherches des utilisateurs. Sans crawlers web, les moteurs de recherche n’auraient aucun moyen de découvrir de nouveaux contenus ou de maintenir leurs index à jour avec les dernières informations en ligne.
L’importance des crawlers web va bien au-delà de la simple fonctionnalité de recherche. Ils servent de fondation à de nombreuses applications numériques telles que les sites de comparaison de prix, les agrégateurs de contenu, les plateformes d’études de marché, les outils d’analyse SEO et les services d’archivage web. Pour les spécialistes du marketing d’affiliation et les opérateurs de réseaux comme ceux utilisant PostAffiliatePro, comprendre le fonctionnement des crawlers est essentiel pour s’assurer que le contenu d’affiliation, les pages produits et les supports promotionnels soient correctement découverts et indexés par les moteurs de recherche. Cette visibilité a un impact direct sur le trafic organique, la génération de leads et, en fin de compte, les opportunités de commissions d’affiliation.
Le processus du crawler web : Exécution étape par étape
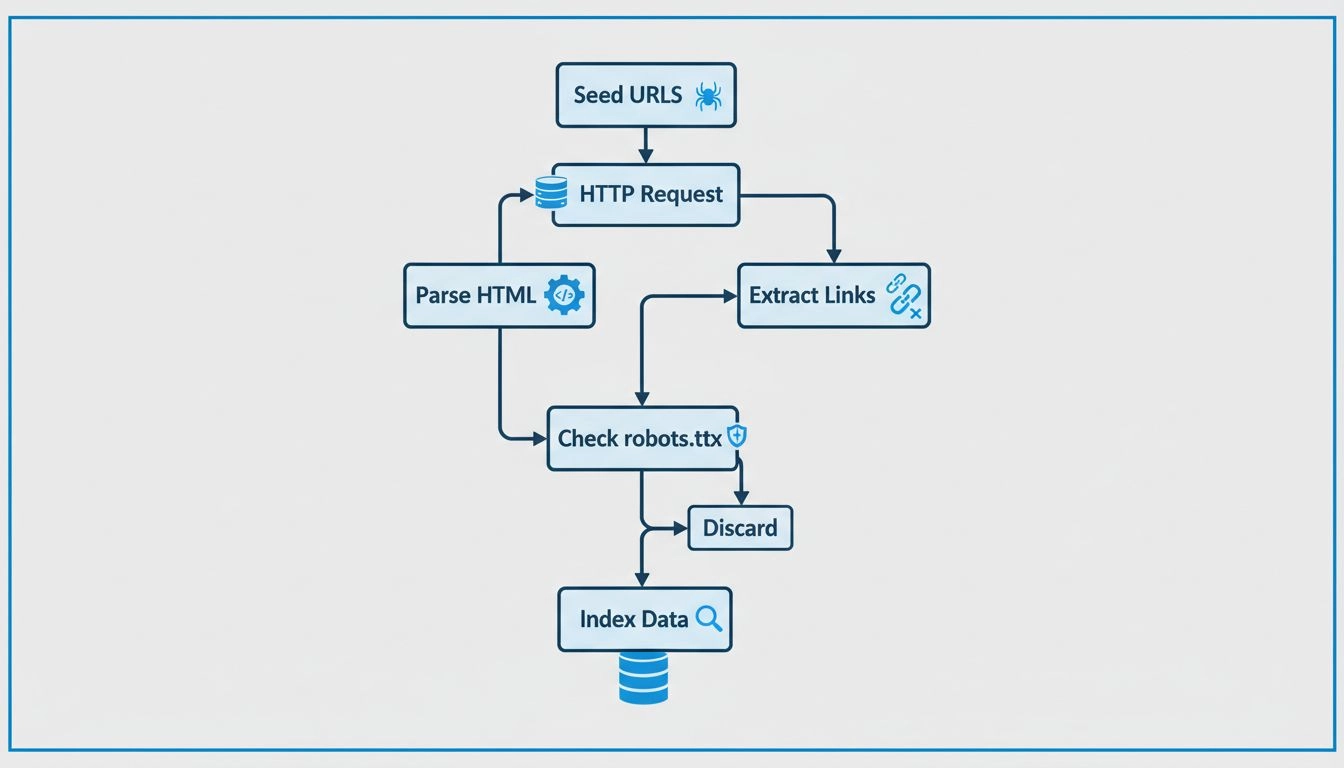
Les crawlers web suivent un processus méthodique et structuré pour explorer systématiquement Internet. Le processus commence par des URLs sources, qui sont des points de départ connus comme les pages d’accueil, les fichiers sitemaps XML ou des pages déjà explorées. Ces URLs sources servent de porte d’entrée pour le parcours du crawler à travers le web. Le crawler maintient une file d’attente d’URLs à visiter, souvent appelée « frontière d’exploration », qui s’agrandit continuellement à mesure que de nouveaux liens sont découverts lors du crawling.
Lorsqu’un crawler atteint une URL, il envoie une requête HTTP au serveur web hébergeant cette page. Le serveur répond en envoyant le contenu HTML de la page, de la même manière qu’un navigateur charge une page lors d’une visite. Le crawler analyse alors ce code HTML pour extraire des informations précieuses, notamment le texte de la page, les balises meta (comme le titre et la description), les images, les vidéos et, surtout, les hyperliens vers d’autres pages. Cette extraction de liens est cruciale car elle permet au crawler de découvrir de nouvelles URLs qui n’ont pas encore été visitées, lesquelles sont alors ajoutées à la file d’attente pour de futures visites.
Étape du processus du crawler
Description
Actions clés
Initialisation
Lancement du processus de crawl
Charger les URLs sources, initialiser la file d’attente
Requête & Récupération
Récupération du contenu de la page
Envoyer des requêtes HTTP, recevoir les réponses HTML
Analyse HTML
Analyse de la structure de la page
Extraire le texte, les métadonnées, les liens, les médias
Extraction de liens
Recherche de nouvelles URLs
Identifier les hyperliens, ajouter à la file d’attente
Vérification robots.txt
Respect des règles du site
Vérifier les permissions avant de visiter
Stockage du contenu
Sauvegarde des informations
Indexer les données dans une base consultable
Priorisation
Détermination des prochaines pages
Classer les URLs par importance et pertinence
Répétition
Poursuite du cycle
Traiter la prochaine URL de la file d’attente
Avant de visiter une nouvelle URL sur un domaine, les crawlers responsables vérifient le fichier robots.txt situé à la racine de ce domaine. Ce fichier contient des instructions utilisées par les propriétaires de sites pour communiquer avec les crawlers sur les pages qui peuvent être explorées et celles à éviter. Par exemple, un propriétaire de site peut utiliser robots.txt pour empêcher les crawlers d’accéder à des pages sensibles, du contenu dupliqué ou des sections gourmandes en ressources susceptibles de surcharger leurs serveurs. La plupart des crawlers légitimes des moteurs de recherche respectent ces instructions afin de maintenir de bonnes relations avec les propriétaires de sites et d’éviter d’engendrer des problèmes de performance.
Lancez votre programme d'affiliation aujourd'hui
Configurez le suivi avancé en quelques minutes. Aucune carte de crédit requise.
Capacités avancées des crawlers et techniques modernes
Les crawlers web modernes ont considérablement évolué pour gérer la complexité des sites contemporains. De nombreux sites utilisent aujourd’hui JavaScript pour générer dynamiquement du contenu après le chargement de la page, ce qui signifie que la réponse HTML initiale ne contient pas tout le contenu de la page. Les crawlers avancés utilisent désormais des navigateurs sans interface graphique (headless browsers) pour exécuter le JavaScript et capturer le contenu chargé dynamiquement, qui ne serait pas visible pour les crawlers traditionnels. Cette capacité est essentielle pour explorer les applications monopages, les tableaux de bord interactifs et les applications web modernes reposant fortement sur le rendu côté client.
Les crawlers mettent en œuvre des algorithmes de priorisation sophistiqués pour optimiser l’utilisation de leur budget de crawl — le nombre limité de pages qu’ils peuvent explorer sur une période donnée. Ces algorithmes tiennent compte de plusieurs facteurs comme l’autorité de la page (déterminée par la qualité et la quantité de liens entrants), la structure de liens internes, la fraîcheur du contenu, le volume de trafic et la réputation du domaine. Les pages à forte autorité et les contenus fréquemment mis à jour sont visités plus souvent, tandis que les pages moins importantes ou statiques peuvent être explorées moins fréquemment voire ignorées. Cette priorisation intelligente permet aux crawlers de concentrer leurs ressources sur le contenu le plus précieux et le plus dynamique.
Le délai d’exploration et la limitation du débit sont des mécanismes importants pour éviter que les crawlers ne surchargent les serveurs web. Les crawlers responsables effectuent des pauses entre les requêtes et respectent les directives de délai d’exploration spécifiées dans les fichiers robots.txt. Ce comportement de crawl courtois protège la performance du site et l’expérience utilisateur en s’assurant que le trafic des crawlers n’épuise pas excessivement les ressources serveur. Les sites lents à charger ou qui renvoient des erreurs peuvent voir leur fréquence d’exploration réduite, les crawlers ralentissant automatiquement pour éviter de causer des problèmes.
Types de crawlers web et leurs fonctions spécialisées
Différents types de crawlers web remplissent des fonctions distinctes dans l’écosystème numérique. Les crawlers web généraux sont déployés par les principaux moteurs de recherche pour explorer l’ensemble d’Internet sans distinction, créant ainsi des index exhaustifs qui alimentent les résultats de recherche. Ces crawlers sont conçus pour une couverture maximale et fonctionnent en continu pour découvrir de nouveaux contenus et mettre à jour les index existants. Les crawlers verticaux ou spécialisés se concentrent sur des secteurs ou des types de contenu spécifiques, tels que les crawlers d’offres d’emploi qui recherchent sur les sites d’emploi, les crawlers de comparaison de prix qui collectent des données tarifaires sur les sites e-commerce, ou encore les crawlers de recherche qui indexent des articles académiques et des publications scientifiques.
Les crawlers incrémentaux se spécialisent dans l’efficacité en se concentrant uniquement sur les contenus nouveaux ou récemment modifiés plutôt que de réexplorer en permanence l’ensemble des sites. Cette approche réduit considérablement la charge serveur et la consommation de bande passante tout en maintenant les index relativement à jour. Les crawlers ciblés utilisent des algorithmes avancés pour rechercher du contenu sur des sujets ou mots-clés précis, en priorisant intelligemment les pages susceptibles de contenir des informations pertinentes. Les crawlers en temps réel surveillent continuellement les sites web et mettent à jour leurs données collectées en temps réel ou quasi réel, ce qui les rend idéaux pour l’agrégation d’actualités ou la veille sur les réseaux sociaux.
Les crawlers parallèles et crawlers distribués représentent l’extrémité la plus lourde en infrastructure du spectre des crawlers. Les crawlers parallèles fonctionnent sur plusieurs machines ou threads simultanément pour augmenter considérablement la vitesse et le débit d’exploration. Les crawlers distribués répartissent la charge de travail sur plusieurs serveurs ou centres de données, ce qui leur permet de traiter efficacement d’énormes volumes de données. Les grands moteurs de recherche comme Google utilisent des architectures de crawlers distribués pour gérer les milliards de pages présentes sur Internet.
Crawlers web et optimisation pour les moteurs de recherche
Les crawlers web jouent un rôle fondamental dans le référencement naturel car ils déterminent quelles pages sont indexées et comment les moteurs de recherche comprennent votre contenu. Si les crawlers ne peuvent pas accéder à vos pages, celles-ci n’apparaîtront pas dans les résultats de recherche, quelle que soit leur qualité ou leur pertinence. Les problèmes fréquents empêchant une indexation correcte incluent des pages bloquées par des directives robots.txt, des liens internes cassés menant à des erreurs 404, des temps de chargement trop longs qui font expirer les crawlers, ou des problèmes de rendu JavaScript empêchant les crawlers de voir le contenu généré dynamiquement.
Les propriétaires de sites peuvent optimiser l’accès des crawlers grâce à plusieurs stratégies clés. Une architecture de site claire avec une hiérarchie de navigation logique aide les crawlers à comprendre les relations et l’importance des pages. Le maillage interne indique aux crawlers quelles pages sont les plus importantes et permet de répartir efficacement le budget de crawl sur l’ensemble du site. Les sitemaps XML listent explicitement toutes les pages importantes, s’assurant ainsi que les crawlers ne ratent aucun contenu, même sur des sites volumineux ou complexes. Des temps de chargement rapides encouragent les crawlers à visiter plus de pages dans leur budget alloué, tandis qu’un contenu frais et régulièrement mis à jour indique qu’un site mérite des visites d’exploration plus fréquentes.
Pour les spécialistes du marketing d’affiliation utilisant des plateformes comme PostAffiliatePro, assurer un accès optimal aux crawlers est crucial pour générer du trafic organique vers les contenus d’affiliation. Lorsque vos pages produits, articles comparatifs et contenus promotionnels sont bien explorés et indexés, ils peuvent se positionner dans les résultats de recherche et attirer un trafic qualifié. Une mauvaise explorabilité peut entraîner des occasions d’indexation manquées et une visibilité réduite pour vos offres d’affiliation.
Règles des crawlers et contrôle par les propriétaires de sites
Les propriétaires de sites disposent de plusieurs mécanismes pour contrôler la façon dont les crawlers interagissent avec leur site. Le fichier robots.txt est l’outil principal, contenant des directives qui précisent quels agents (types de crawlers) peuvent accéder à quelles parties du site. Un fichier robots.txt bien configuré peut empêcher les crawlers de gaspiller des ressources sur du contenu dupliqué, des environnements de préproduction ou des pages gourmandes en ressources, tout en leur permettant d’explorer librement le contenu important. La balise meta robots apparaît dans le HTML de chaque page et offre un contrôle au niveau de la page, permettant d’exclure certaines pages de l’indexation ou d’ignorer leurs liens.
L’attribut de lien nofollow indique aux crawlers de ne pas suivre certains hyperliens, ce qui est utile pour éviter que les crawlers ne suivent des liens vers des sites externes non fiables ou du contenu généré par les utilisateurs. Ces mécanismes de contrôle fonctionnent ensemble pour offrir aux propriétaires un contrôle précis du comportement des crawlers tout en maintenant de bonnes relations avec les moteurs de recherche. Toutefois, il est important de noter que les scrapers malveillants et les bots agressifs ignorent souvent totalement ces directives, ce qui explique pourquoi des mesures de sécurité supplémentaires telles que la limitation de débit et la détection de bots peuvent s’avérer nécessaires.
Impact sur le marketing d’affiliation et l’exploitation des réseaux
Pour les opérateurs de réseaux d’affiliation et les marketeurs, comprendre le comportement des crawlers web influence directement le succès commercial. Les crawlers déterminent la visibilité des pages produits affiliées, du contenu comparatif et des supports promotionnels dans les résultats de recherche. Lorsque les utilisateurs de PostAffiliatePro optimisent leurs sites d’affiliation pour un crawl correct, ils augmentent la probabilité que leur contenu soit découvert par les moteurs de recherche et classé sur des mots-clés pertinents. Cette visibilité organique attire un trafic qualifié vers les offres d’affiliation, multipliant les opportunités de conversion et les gains de commissions.
Les réseaux d’affiliation tirent parti de l’activité des crawlers à plusieurs niveaux. Les crawlers des moteurs de recherche aident à diffuser le contenu d’affiliation sur Internet, augmentant la notoriété de la marque et sa portée. Les crawlers permettent aussi aux sites de comparaison de prix et aux agrégateurs de contenu de découvrir et de mettre en avant les produits affiliés, créant ainsi des sources de trafic supplémentaires. Cependant, les spécialistes de l’affiliation doivent aussi se méfier des crawlers et scrapers malveillants susceptibles de copier le contenu affilié ou de pratiquer la fraude au clic. La mise en place de limites de débit, de systèmes de détection de bots et de mesures de protection du contenu permet de préserver l’intégrité du réseau d’affiliation tout en laissant les crawlers légitimes fonctionner correctement.
PostAffiliatePro offre des capacités de suivi et de reporting complètes qui complètent une bonne optimisation pour les crawlers. En veillant à ce que votre contenu d’affiliation soit correctement exploré et indexé, combiné au suivi avancé et à l’analytique de PostAffiliatePro, vous pouvez maximiser la visibilité et la rentabilité de votre réseau d’affiliation. Le suivi des commissions en temps réel et les rapports intelligents de la plateforme vous aident à comprendre quels canaux d’affiliation génèrent le trafic le plus précieux, ce qui vous permet d’optimiser votre stratégie réseau en conséquence.
Optimisez votre réseau d’affiliation avec PostAffiliatePro
Tout comme les crawlers web découvrent et indexent systématiquement le contenu, PostAffiliatePro suit et optimise systématiquement vos relations d’affiliation. Notre plateforme offre un suivi en temps réel, des rapports complets et une gestion intelligente des commissions pour vous aider à bâtir un réseau d’affiliation prospère.
Les crawlers et leur rôle dans le classement des moteurs de recherche
Les crawlers accumulent des données et des informations sur Internet en visitant des sites web et en lisant leurs pages. Découvrez-en plus à leur sujet.
Spiders SEO : Pourquoi sont-ils importants pour votre site
Les spiders sont des robots créés pour le spamming, pouvant causer de nombreux problèmes à votre entreprise. Découvrez-en plus à leur sujet dans cet article....
Qu'est-ce que le Google Spider ? Guide complet sur l’exploration de Googlebot
Découvrez ce qu’est le Google Spider (Googlebot), comment il explore et indexe les sites web, et pourquoi il est essentiel pour le SEO. Apprenez à optimiser vot...
9 min de lecture
Vous serez entre de bonnes mains !
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.