Pourquoi les robots d’indexation web sont-ils appelés « spiders » ? Comprendre les crawlers
Découvrez pourquoi les robots d’indexation web sont appelés spiders et comment ils parcourent Internet. Comprenez le fonctionnement des crawlers des moteurs de recherche et leur importance pour le SEO et le marketing d’affiliation.
Pourquoi les appelle-t-on spiders informatiques ? On les appelle ainsi parce qu’ils « rampent » sur le web.
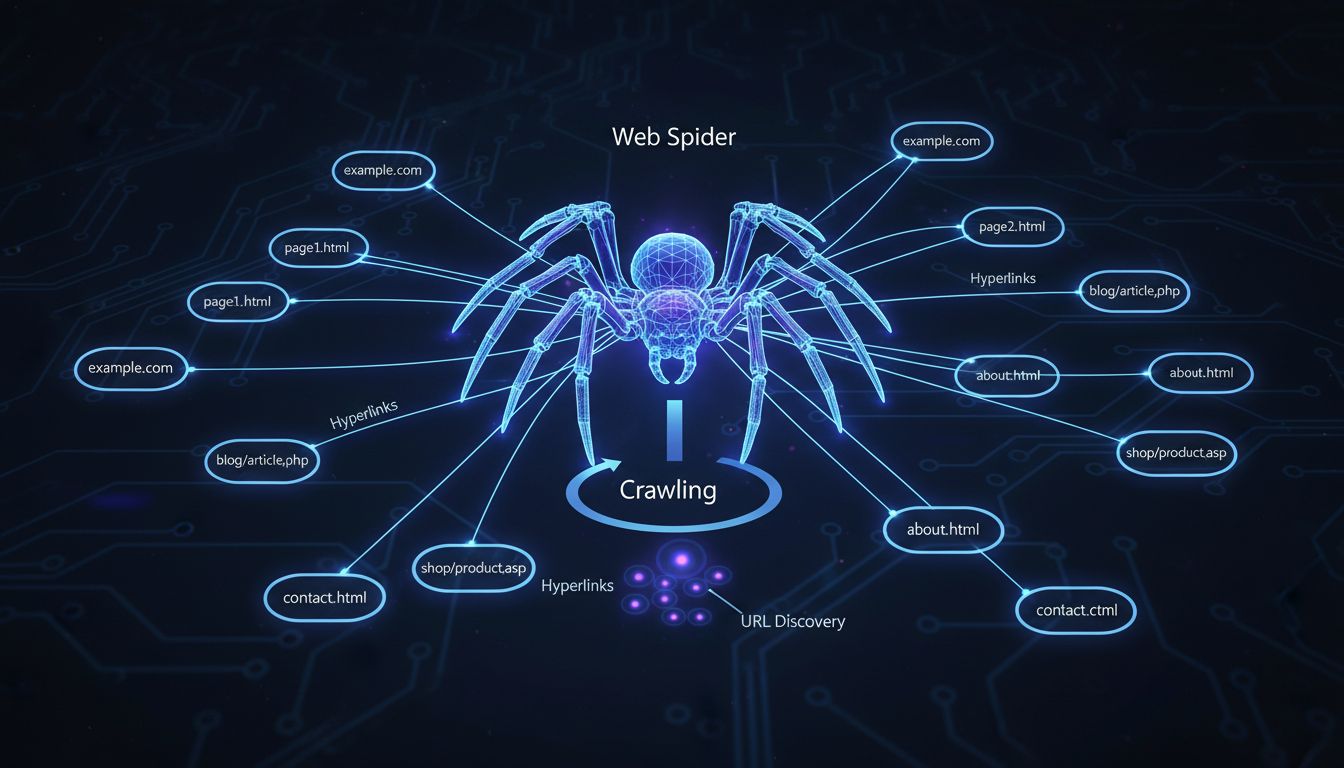
Les spiders web sont appelés spiders informatiques parce qu’ils « rampent » sur Internet en suivant les hyperliens d’une page à l’autre, comme une araignée se déplace sur sa toile. Ces programmes automatisés explorent systématiquement les sites pour découvrir et indexer le contenu destiné aux moteurs de recherche.
Comprendre la métaphore de l’araignée
Le terme « spider informatique » provient d’une analogie ingénieuse qui décrit parfaitement la façon dont ces programmes automatisés fonctionnent sur Internet. Tout comme une véritable araignée se déplace sur sa toile en suivant des fils et des connexions, un spider web navigue sur Internet en suivant les hyperliens d’une page web à l’autre. Cette métaphore est devenue si intuitive qu’elle constitue désormais la terminologie standard utilisée par les développeurs web, les professionnels du SEO et les marketeurs digitaux à travers le monde. Ce nom saisit l’essence du comportement du crawler d’une manière immédiatement compréhensible, tant pour les publics techniques que non techniques. En comprenant ce concept fondamental, vous réalisez à quel point l’infrastructure d’Internet reflète élégamment certains systèmes naturels.
Comment les spiders parcourent Internet
Les spiders web fonctionnent selon un processus systématique et méthodique qui commence par une liste initiale d’URL connues. Le crawler commence par visiter ces premières pages web et examine attentivement leur contenu et leur structure. Au fur et à mesure qu’il traite chaque page, le spider identifie tous les hyperliens présents et les ajoute à une file d’attente d’URL à visiter ensuite. Ce processus se répète continuellement, permettant au spider d’explorer toujours plus profondément le web à chaque itération. Le spider crée ainsi une cartographie d’Internet en suivant ces connexions, tout comme un explorateur trace de nouveaux territoires en suivant des sentiers. Cette approche systématique garantit que les moteurs de recherche peuvent découvrir et cataloguer des millions de nouvelles pages chaque jour.
Composant du crawler
Fonction
Objectif
File d’attente d’URL
Stocke la liste des pages à visiter
Organise la séquence de crawl
Parseur
Analyse le contenu de la page et le HTML
Extrait les liens et métadonnées
Indexeur
Stocke les informations de page
Crée une base de données consultable
Planificateur
Détermine la fréquence de crawl
Gère l’allocation des ressources
User-Agent
Identifie le crawler
Communique avec les serveurs
Le processus technique du crawling web
Avant qu’un spider web ne commence son opération de crawl, les développeurs doivent établir des instructions claires et pré-définies qui guident le comportement du spider. Ces instructions déterminent quelles pages doivent être explorées, à quelle fréquence les revisiter, et quelles informations extraire de chaque page. Le crawler exécute ensuite ces instructions automatiquement, suivant l’algorithme tel qu’il a été programmé. Lorsqu’un spider visite un site web, il vérifie d’abord le fichier robots.txt, qui est un fichier texte indiquant les règles d’accès du crawler. Ce protocole, connu sous le nom de robot exclusion protocol, permet aux propriétaires de sites de communiquer leurs préférences concernant les zones du site à explorer ou à éviter. Les informations recueillies par le crawler dépendent entièrement des instructions qui lui sont fournies, rendant la phase de configuration cruciale pour obtenir les résultats souhaités.
Différents types de spiders web
Les spiders web se déclinent en plusieurs formes, chacune conçue pour des usages et des applications spécifiques. Les spiders des moteurs de recherche comme Googlebot sont les plus connus, utilisés par les principaux moteurs de recherche pour découvrir et indexer les pages web pour les résultats de recherche. Les crawlers spécialisés, quant à eux, limitent leur exploration à des sujets ou des zones précises d’Internet, créant des index détaillés de contenus de niche. Les spiders d’analyse web aident les webmasters à surveiller leurs propres sites en suivant des indicateurs tels que les visites, les liens brisés et la performance des pages. Les spiders de comparaison de prix collectent automatiquement les tarifs auprès de plusieurs vendeurs, permettant aux sites comparateurs de proposer des informations actualisées du marché. Les spiders de validation d’e-mails vérifient les adresses électroniques et détectent les problèmes de délivrabilité. Chaque type de spider a un rôle distinct dans l’écosystème digital, et comprendre ces différences aide les propriétaires de sites à optimiser leur site pour les crawlers appropriés.
Pourquoi les moteurs de recherche dépendent des spiders web
Les moteurs de recherche ne pourraient pas fonctionner sans spiders web, car ce sont ces programmes automatisés qui découvrent les nouveaux contenus et actualisent les index de recherche. Lorsque vous effectuez une recherche, le moteur ne parcourt pas réellement Internet en temps réel. Il consulte plutôt un index qui a été créé par les spiders lors de leurs visites et de leur catalogage de milliards de pages web. Sans spiders, les moteurs de recherche n’auraient aucun moyen de savoir quel contenu existe sur Internet ni comment l’organiser pour qu’il soit retrouvé. La capacité du spider à suivre les hyperliens permet la découverte automatique de nouvelles pages sans qu’une soumission manuelle soit nécessaire. Ce processus automatisé de découverte est ce qui rend Internet consultable et accessible à des milliards d’utilisateurs dans le monde. L’efficacité et la rapidité des spiders web influent directement sur la vitesse à laquelle un nouveau contenu apparaît dans les résultats de recherche.
L’importance des spiders web pour le SEO et le marketing digital
Pour les propriétaires de sites et les marketeurs digitaux, comprendre les spiders web est essentiel car ce sont ces crawlers qui déterminent si votre contenu apparaîtra dans les résultats de recherche. Si un spider de moteur de recherche ne peut pas explorer votre site, vos pages ne seront pas indexées et n’apparaîtront pas dans les résultats, quelle que soit la qualité de votre contenu. C’est pourquoi les professionnels du SEO accordent une grande importance à rendre les sites « crawlables » en assurant une structure claire, des temps de chargement rapides et une navigation intuitive. Les affiliés, en particulier, tirent profit de la compréhension du comportement des spiders car cela influe directement sur la découverte et le classement de leurs pages d’affiliation. PostAffiliatePro comprend que le succès d’un programme d’affiliation repose sur la visibilité, et notre plateforme vous aide à optimiser votre réseau d’affiliés pour que les spiders des moteurs de recherche puissent facilement découvrir et indexer votre contenu d’affiliation. En rendant vos pages d’affiliation accessibles aux crawlers, vous augmentez les chances que de nouveaux affiliés et clients trouvent votre programme via la recherche organique.
Gérer et contrôler l’activité des spiders web
Les propriétaires de sites disposent de plusieurs outils pour gérer la façon dont les spiders web interagissent avec leur site. Le fichier robots.txt est le mécanisme principal pour communiquer vos préférences, permettant de spécifier quelles pages doivent être explorées ou ignorées. La balise meta noindex permet un contrôle supplémentaire en empêchant l’indexation de certaines pages même si elles sont explorées. Pour les pages qui doivent être explorées mais pas indexées, l’attribut nofollow peut être utilisé sur les liens pour empêcher les spiders de suivre ces connexions particulières. Les propriétaires de sites peuvent aussi utiliser la Google Search Console et d’autres outils pour surveiller l’activité des crawlers et identifier les problèmes d’indexation. Cependant, il est important de noter que si ces outils aident à gérer les spiders légitimes des moteurs de recherche, les bots malveillants et scrapers peuvent ignorer ces directives. C’est pourquoi de nombreux sites mettent en place des mesures de sécurité et des systèmes de gestion des bots pour se protéger contre les crawlers nuisibles tout en autorisant l’accès aux spiders bénéfiques.
Différence entre spiders et scrapers
Bien que spiders web et scrapers collectent tous deux automatiquement des données sur les sites, ils servent des objectifs très différents et opèrent selon des règles éthiques distinctes. Les spiders web, surtout ceux des moteurs de recherche, respectent le protocole robots.txt et tiennent compte des préférences des propriétaires de sites sur le contenu à explorer. Les scrapers, en revanche, ignorent souvent ces directives et copient l’intégralité des pages pour les republier ailleurs, ce qui constitue une violation du droit d’auteur et du droit de propriété intellectuelle. Les spiders collectent généralement et organisent les métadonnées des pages, tandis que les scrapers copient l’ensemble du contenu visible. Les spiders des moteurs de recherche sont généralement considérés comme bénéfiques car ils améliorent la visibilité des sites, tandis que les scrapers sont vus comme nuisibles car ils volent du contenu et peuvent dégrader les performances du site. Comprendre cette distinction est important pour les propriétaires de sites qui doivent distinguer le trafic des crawlers légitimes de l’activité malveillante des bots. PostAffiliatePro aide les gestionnaires d’affiliation à surveiller et gérer le trafic sur leurs pages d’affiliation, en s’assurant que les spiders légitimes peuvent accéder à votre contenu tout en protégeant contre le scraping malveillant.
Maximisez la visibilité de votre réseau d’affiliation
Tout comme les spiders web découvrent et indexent votre contenu, PostAffiliatePro vous aide à découvrir et gérer l’ensemble de votre réseau d’affiliés. Suivez chaque interaction de crawler et optimisez la performance de votre programme d’affiliation grâce à notre plateforme leader du secteur.
Pourquoi les robots d’indexation web sont-ils appelés araignées ? Comprendre la technologie d’indexation du web
Découvrez pourquoi les robots d’indexation web sont appelés araignées, comment ils fonctionnent et leur rôle essentiel dans l’indexation des moteurs de recherch...
Spiders SEO : Pourquoi sont-ils importants pour votre site
Les spiders sont des robots créés pour le spamming, pouvant causer de nombreux problèmes à votre entreprise. Découvrez-en plus à leur sujet dans cet article....
Qu'est-ce qu'un virus informatique Spider ? Définition, menaces et guide de protection
Découvrez ce que sont les virus informatiques spider, comment ils se propagent sur les réseaux, et trouvez des stratégies de protection efficaces. Guide complet...
9 min de lecture
Vous serez entre de bonnes mains !
Rejoignez notre communauté de clients satisfaits et offrez un excellent support client avec Post Affiliate Pro.